一个看不懂的瞬间
入职第二年,我第一次盯着 Spark UI 看一个跑了一小时还没出结果的任务。
Stage 163 的 task 时间分布是这样的:
- min:0 ms
- median:6.8 秒
- max:2 分钟
总数据 14 亿行,35.9 GiB,1000 个文件,1 个分区。
我心里有一个模糊的感觉:这个不对。但我说不清楚哪里不对。Leader 走过来扫了一眼,说「数据倾斜,文件大小不均」,然后就走了。
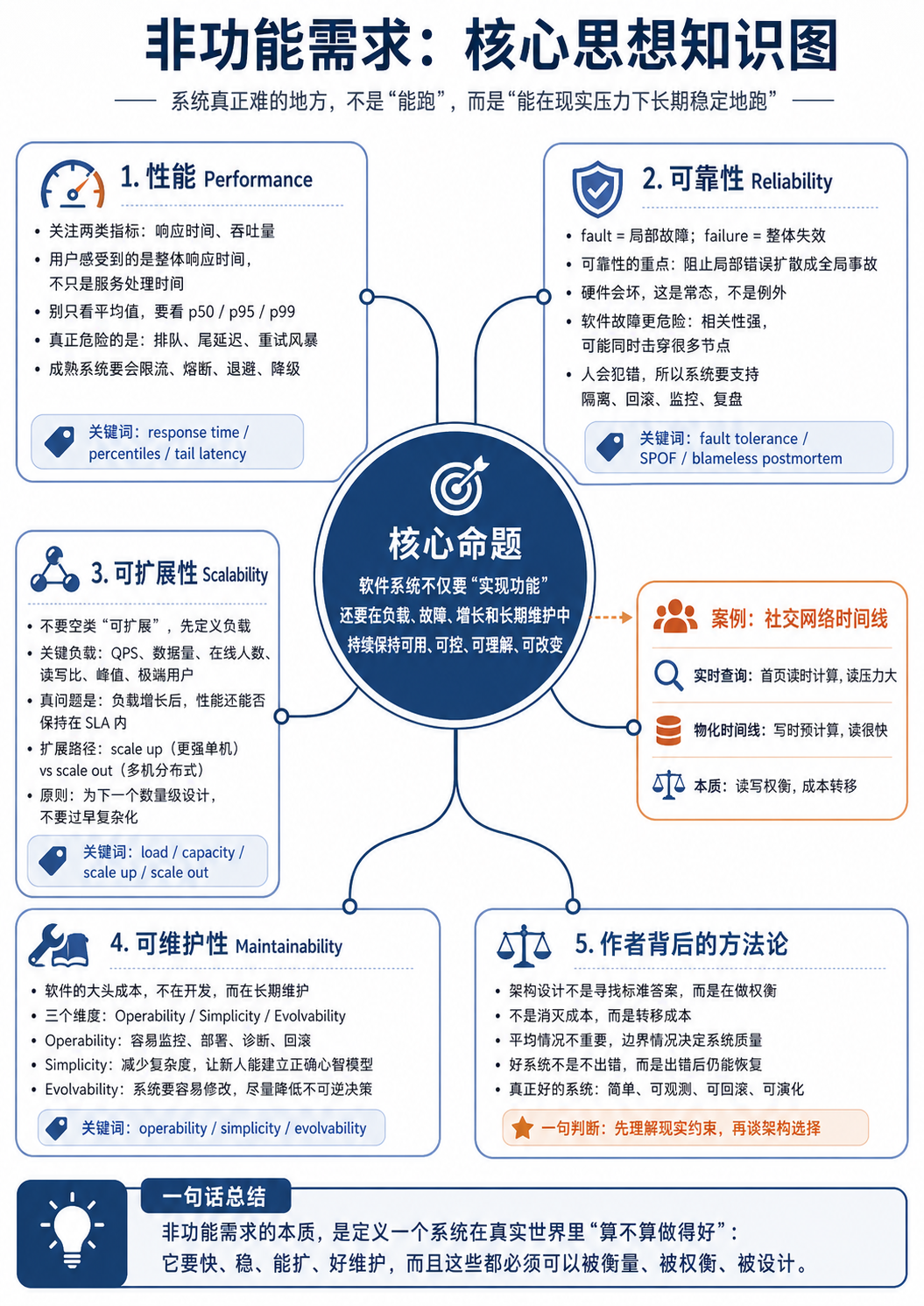
那时候我不知道,这种「说不清楚的不对劲」,在一本叫 Designing Data-Intensive Applications 的书里,有一整章在讲。它叫 非功能需求。
这篇文章不是 DDIA 的读书笔记,是工作五年回头看,我撞过的那些墙,原来都有名字。
我把这一章拆成五件事讲。前四件是我撞过的墙——性能、可靠性、可扩展性、可维护性。第五件是撞完之后,我才慢慢看懂的一个东西: 所有「解决」都是成本转移 。
一、性能:平均值是骗人的
我那时候是怎么看「快慢」的
刚入行的时候,判断一个任务跑得好不好,我只看一个数:总时长。
跑了 30 分钟,叫慢。跑了 5 分钟,叫快。跑了 1 分钟,叫「今天集群挺空」。
如果有人问我「任务表现怎么样」,我会说「平均 5 分钟左右」。这个「平均」是我自己脑子里估的,不是算出来的。
撞墙的那一天
回到开头那个 Stage 163。
总时长 1 小时,我以为「是任务本身就重」。但 Leader 让我点进去看 task 级别的分布。
total: 1.03 hmin: 0 msmed: 6.8 smax: 2.0 m这一秒我才意识到:绝大多数 task 几秒钟就跑完了,但有几个 task 花了 2 分钟,把整个 stage 拖在那里。
而且更刺眼的是 HashAggregate 的内存:
min: 0.0 Bmed: 640.0 MiBmax: 640.0 MiBmin 是 0,意思是有些 task 根本没分到数据,在那里空转。max 是 640 MiB,意思是少数 task 在硬扛。
根因后来查清楚了:这张 ODS 表只读了 1 个分区,但这 1 个分区里有 1000 个文件,文件大小不均匀。Spark 按文件切 task,文件大的 task 就成了那 2 分钟。
这个概念给了我什么
DDIA 第二章里讲性能,有两件事我看完才豁然开朗。
第一件,响应时间不是一个数,是一个分布。
p50(中位数)告诉你「典型用户感觉怎么样」,p99 告诉你「最差的那 1% 感觉怎么样」。如果你只看平均值,你会被那些「绝大多数都很快」的场景骗到——平均 5 秒看起来不错,但 p99 可能是 5 分钟。而那 1% 慢的请求,往往就是数据最多、最有价值的那批用户。
第二件,叫 tail latency amplification(尾延迟放大)。
如果一个用户请求要调 10 个后端服务,只要其中一个慢,整个请求就慢。哪怕每个服务的 p99 只有 1%,10 个并行调用里「至少有一个慢」的概率会接近 10%。
这个概念在大数据里有个工业版的名字,叫 数据倾斜 。Spark stage 等的不是平均 task,是最慢那个 task。一千个 task 里有一个跑 2 分钟,这个 stage 就要 2 分钟。
现在我看任务慢
从这一刻起,我看任务慢,第一个动作不再是「加资源」。
第一个动作是看分布。min/p50/p95/max 拉出来看一眼,马上知道是「整体慢」还是「长尾慢」。这两种慢的根因和解法完全不一样。
整体慢,是资源或者算法问题。长尾慢,是分布问题——数据倾斜、文件不均、热点 key、个别慢节点。加资源对长尾慢基本没用。
二、可靠性:一个用户名能干掉整个 application
我那时候是怎么看「挂了」的
刚入行的时候,任务挂了我就重跑。重跑不行就改参数。改参数不行就找 Leader。
我心里默认一个朴素观念:挂了就是有 bug,修了 bug 就不会挂。
撞墙的那一天
有一次一个 Spark 作业怎么都跑不起来,日志最后一行是:
Max number of executor failures (120) reached我以为是内存不够。调大 executor.memory,没用。怀疑数据倾斜,改 SQL,没用。
后来翻 YARN 日志才看到根因:
Can't get user information ydy_ads_user02 - No such file or directoryUser ydy_ads_user02 not foundexitCode=255集群里某一个节点上,没有 ydy_ads_user02 这个 Linux 用户。executor 一调度到那台机器,container 直接启动失败,退出码 255。YARN 把它标记成失败,再调度,再失败。撞够 120 次,整个 application 被 YARN 杀掉。
整个集群几百台机器,就一台机器缺这一个用户。
这个概念给了我什么
DDIA 把这件事拆成两个词,看完我憋了一口气:
- fault:一个局部坏了。比如那台机器缺用户。
- failure:整个系统不能给用户提供服务了。比如 application 被 YARN 杀掉。
这两个词在中文里都翻译成「故障」,所以平常我们说话的时候根本分不开。但工程上它们差得远。
好系统不是不出 fault,是不让 fault 升级成 failure。
那台缺用户的机器是 fault,无法避免——几百台机器配置稍有偏差是常态。但 YARN 把这个 fault 处理成「反复重试 120 次直到 application 死」,这是设计选择。如果加上节点黑名单(撞过 N 次的机器跳过),fault 就被关在 fault 里,不会传染成 failure。
还有一种更阴险的情况,DDIA 里专门讲了:软件故障的相关性比硬件故障可怕。
硬盘坏一块,其他硬盘大概率没事。但软件 bug 是所有节点同时中招——同一个 Kerberos ticket 过期、同一个 leap second bug、同一个版本的固件缺陷。一个节点中招就是一千个节点中招。这种 fault 没法靠「重试到别的节点」解决,因为别的节点也一样烂。
现在我看线上事故
从这一刻起,我修事故第一个问题不再是「哪里坏了」。
第一个问题是:这个坏怎么扩散的。一个节点的 fault,为什么变成整个 application 的 failure?中间漏了哪一道防线?是没有黑名单?是重试次数没上限?是依赖没隔离?
修单点的坏,只是修了今天这次。修扩散路径,才是修了未来一万次类似的坏。
三、可扩展性:加机器没用的那一天
我那时候是怎么看「扩展」的
刚入行的时候,我觉得「可扩展」就是「加机器」。
慢了?加 executor。存不下?加节点。扛不住流量?加副本。这个心智模型简单粗暴,而且在小规模下永远是对的。
撞墙的那一天
有一次任务跑不动了,报错是 HDFS 配额满。
我那个用户的配额是 300GB。我去看实际占用,以为是数据多了,结果一看 .staging 目录占了 281.9 GB。
.staging: 28.4 G 281.9 G (含3副本).staging 是 MapReduce 任务跑起来时存中间数据的目录,任务结束会自动清理。但如果任务异常中断,这些中间数据就留下了。
我列出来一看,里面是几千个 job_1737747793915_XXXXX 目录,全是同一批 ResourceManager 启动后跑过的任务残留。每个 38 MB,几千个加起来 280 GB。
这不是「数据多了」,是「系统行为没设计好」。每次任务异常中断都欠一笔债,几年下来欠到一起,就把配额吃光了。
而且这个时候你加机器、加配额都没用——因为漏的不是容量,是回收机制。
这个概念给了我什么
DDIA 第二章里讲 scalability,有一句话我记到现在:
可扩展性不是「X 是不是可扩展」,是「如果系统这样增长,我们的应对路径是什么」。
scalability 不是一个属性,是一个过程。
而且更反常识的是: 扩展瓶颈往往不在 CPU 或内存上,而在某个共享资源上 。
那次 HDFS 配额是一个共享资源到顶了。还有一次我做实时入库,瓶颈不是 ClickHouse 总吞吐,而是单分区的写入上限——你机器再多,所有写都挤一个分区,该卡还是卡。再有一次跨表 join 慢,不是数据多,是 broadcast 的小表超过了 driver 的内存阈值,自动退化成 SortMergeJoin。
这些都是「加机器没用」的场景。因为瓶颈是结构性的,不是资源性的。
DDIA 还讲了另一句很重的话:
每涨一个数量级,架构都要重想一次。
支撑 1 万用户的架构,撑不到 10 万。撑得住 10 万的架构,撑不到 100 万。这不是因为前面的人没设计好,是不同数量级面对的瓶颈本来就不一样。1 万用户的瓶颈是单机性能,100 万用户的瓶颈是分片策略,1 亿用户的瓶颈是跨机房一致性。
现在我做容量评估
从这一刻起,我做容量评估第一个问题不再是「要多少台机器」。
第一个问题是:哪个东西先到顶。
是 CPU 先到顶,还是磁盘 IO?是单分区写入先到顶,还是 shuffle 网络?是 driver 内存先到顶,还是 metastore 连接数?
找到那个最先到顶的东西,才知道接下来该往哪里加资源,或者更可能——该改架构了。
四、可维护性:那张没人敢动的拉链表
我那时候是怎么看「代码质量」的
刚入行的时候,我对「好代码」的定义就是「能跑」。
注释能省就省,变量名能短就短,设计文档能不写就不写。我的逻辑是:「反正代码就在这里,要看自己看就行了。」
撞墙的那一天
我自己构建了一张用户终端拉链表。结构很简单:
CREATE TABLE dws_rh_user_terminal_scd ( msisdn STRING COMMENT '手机号', device_brand STRING COMMENT '终端品牌', device_model STRING COMMENT '终端型号', device_name STRING COMMENT '终端名称', start_time STRING, end_time STRING)这张表的逻辑是:用户换了手机就开一条新的拉链记录,没换就保持上一条。
下游有几十个看板和模型用这张表算「换机率」、「老用户留存」、「机型流转」。
跑了一年多,有一天有人发现「换机率」突然飙高,又突然回落,完全没规律。
我去查,发现一个具体的问题:同一个 device_name(比如「iPhone 13」),对应多个不同的 device_model。换链判断当时是基于 device_model 写的,所以同一台 iPhone 13,只是 model 字段格式从 MGTE3CH/A 变成 MGTE3CH,系统就以为用户换机了,生成了一条新拉链。
我自己已经完全忘记这个判断当初为什么用 device_model 而不是 device_name。
这个概念给了我什么
DDIA 把可维护性拆成三个词,我看完才发现,三个我都没做到:
- Operability:容易运维。出了问题能快速诊断。
- Simplicity:简单。新人能在合理时间内建立正确心智模型。
- Evolvability:容易演进。需求变了能改。
拉链表的本意是省存储——把每天的全量快照换成只记录变化。但这层「省」换来的是运维复杂度,上面这三件事我都没做到:
出问题难诊断——日志里没有任何「为什么这一条记录被切链」的痕迹,只能反推。新人看不懂——表注释只写「终端 model 型号」,看不出它和 device_name 的关系。改不动——下游耦合得太深,改一个字段要重算一年的下游。
但 DDIA 里讲可维护性还有一句更狠的话:
软件的大头成本不在写出来那一刻,在写完之后的每一天。
我们这个行业有一个集体幻觉:写代码的工程师值得尊敬,改代码的工程师比较 low。但事实是, 绝大多数代码的总投入,90% 花在它写完之后 。
现在我建表
从这一刻起,我写表设计文档第一个问的问题不是「现在怎么用」。
第一个问题是:三年后接手的人能看懂吗。字段为什么这么设计、判断准则的边界条件是什么、为什么选 A 不选 B——这些写进文档,不是为了今天的我,是为了三年后那个跟我素未谋面、却要维护我代码的工程师。
而且很多时候我自己就是那个三年后的工程师。
五、所有「解决」都是成本转移
前面四件事讲完了。讲到这里,我想把整章拎出来再看一眼。
DDIA 第二章用的开篇案例,是社交网络的 home timeline。它讲了两种实现方案:
- 方案 A:用户每次刷新,实时去查「我关注的所有人最近发了啥」。
- 方案 B:有人发推的时候,主动把这条推 fan-out 到所有关注者的「信箱」里。用户刷新时直接读自己的信箱。
方案 A 写少读多——发推便宜,刷新贵。方案 B 写多读少——发推贵,刷新便宜。
书里有一句话,我第一次读没在意,第二次读才咂摸出味道:
物化视图加快了读,但代价是要在写的时候做更多工作。
这句话翻译成大白话就是: 没有任何性能提升是免费的。所有「加快」都是把成本从一个地方搬到另一个地方 。
这个观点一旦装进脑子,你看什么都不一样了
数仓的 ODS→DWD→DWS→ADS 分层,本质上就是 home timeline 的工业版——把查询时的计算成本,提前转移到写入时的计算和存储上。每天凌晨那几小时跑批,就是在替业务方「提前付账」。
ClickHouse 的 MergeTree 是成本转移——把查询时的排序成本,转移到后台 merge 进程上。所以 ClickHouse 查得快,代价是写入后有一段「还没整理好」的窗口,以及后台进程要持续吃 CPU。
三副本是成本转移——把「机器一定不能坏」的成本,转移到「多花两倍存储 + 一致性协议复杂度」上。
我那张拉链表也是成本转移——把每天全量扫描的成本,转移到每天只更新变化部分。但代价是引入了「换链判断」这个新的复杂度,而那个 device_name/device_model 的事故,就是这个复杂度反咬了一口。
前面四节讲的所有「应对手段」,都是成本转移:
- 用 p99 替代平均值——把「忽略长尾」的认知成本,转移到「维护多个分位指标」的工程成本上。
- 用 fault tolerance 防止 fault 升级成 failure——把「出 fault 就崩」的事故成本,转移到「维护重试、隔离、降级」的设计成本上。
- 用分布式架构应对单点瓶颈——把「单机扛」的硬件成本,转移到「协调一致性、网络分区、数据分片」的复杂度成本上。
- 用清晰的设计文档维持 evolvability——把「以后改不动」的债务成本,转移到「今天多花半天写文档」的当下成本上。
新人最容易犯的错
新人最容易犯的错,不是「不会」,是觉得有「银弹」。
看到 ClickHouse 快就以为它万能。看到分布式好就以为加机器就能扩展。看到三副本稳就以为不会丢数据。看到一个新框架就以为能解决一切问题。
这些都是「成本不会自己消失」这个朴素常识的反面。
每当你看到一个东西「很神奇地解决了某个问题」,停下来问一句: 它把成本转移到哪里去了?
- 转移到了写入路径吗?
- 转移到了存储成本吗?
- 转移到了运维复杂度吗?
- 转移到了未来某个继任者头上吗?
这一句话问出来,你对这个东西的理解,会比读十篇软文都深。
这就是为什么 DDIA 第二章讲的那五个词——performance、reliability、scalability、maintainability,加上贯穿其中的 trade-off——是工程师的元语言。它们不是用来「评估系统」的标尺,是用来把「说不清楚的不对劲」叫出名字的工具。
写在最后
工作五年回头看,我没记住 DDIA 第二章里多少定义。
我记住的是:
当我看到 Spark UI 上 max 2 分钟时,能立刻问一句「分布是什么样的」;
当我看到一个 application 挂掉时,能立刻问一句「这是 fault 还是 failure」;
当老板说「加机器吧」时,能立刻问一句「哪个东西先到顶」;
当我建一张表时,能立刻问一句「三年后接手的人能看懂吗」;
当有人说「这个方案完美」时,能立刻问一句「成本转移到哪里去了」。
这五个词不是用来背的,是用来命名的。 当你能给「说不清楚的不对劲」叫出名字,你就赢了一半。