0. 开篇
Feynman 在 1985 年的一次研讨会上说过:
“A computer does not primarily compute… they primarily are filing systems.”
数据库表面上做两件事:写入数据,读取数据。
但真正困难的是:如何让未来的读取变快,同时不让当前的写入变慢太多。
最简单的数据库可以只是一个文件:
db_set () { echo "$1,$2" >> database; }db_get () { grep "^$1," database | sed -e "s/^$1,//" | tail -n 1}写入很快,因为只是把一行追加到文件末尾。读取很慢,因为要从头到尾扫描整个文件。如果数据有 1 亿条,平均要扫 5000 万行才能找到一条记录。
为了让读取变快,需要建立索引。但索引不是免费的,它会带来三个代价:
- 占用额外存储
- 写入时需要同步维护索引
- 增加系统复杂度
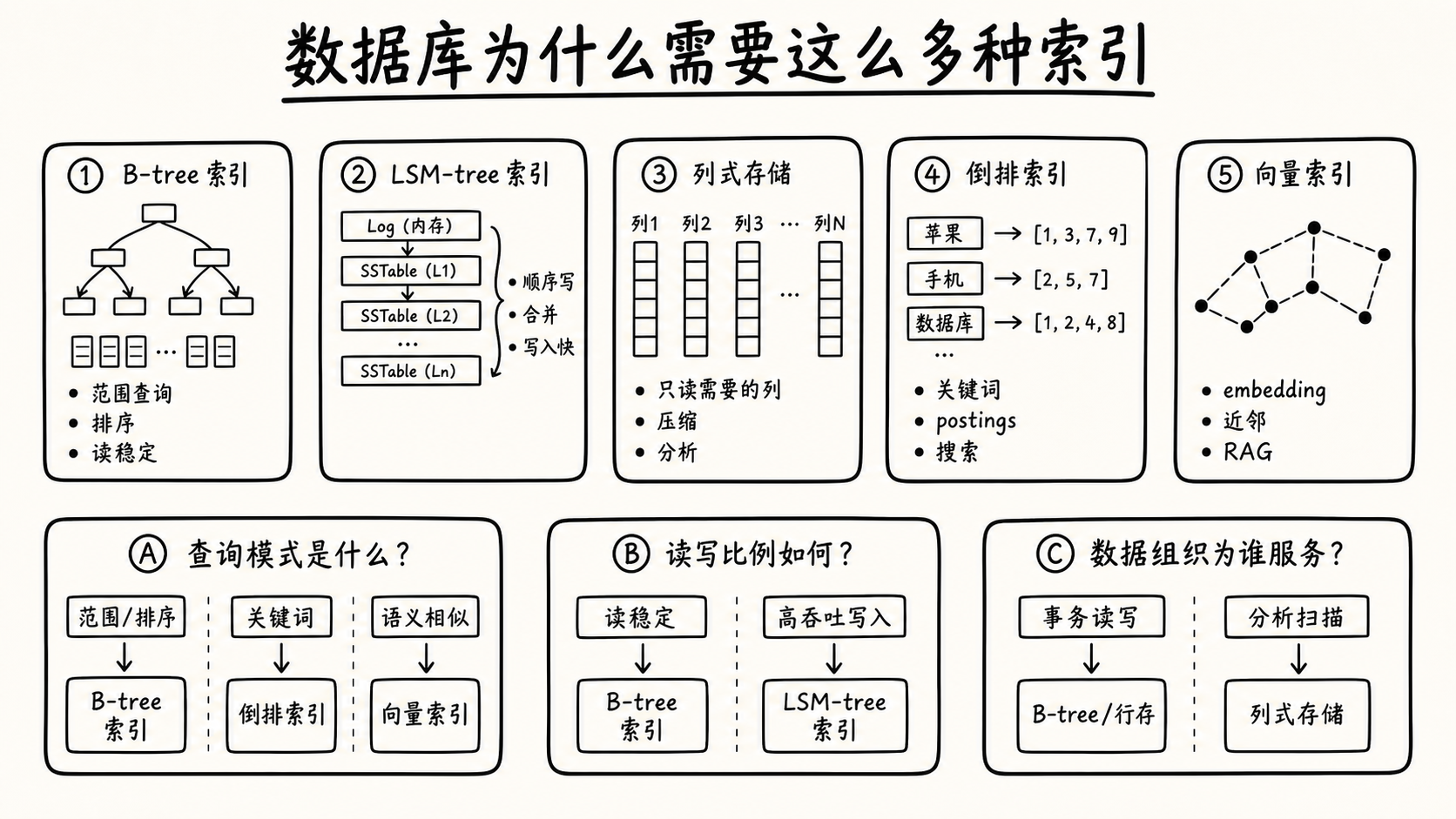
因此,数据库不会自动为所有列建立索引。建哪个索引,取决于查询是什么样子的。
本文围绕一个问题展开:
为什么数据库需要 B-tree、LSM-tree、列存、倒排索引、向量索引这些不同结构?
答案是:
不同的查询有不同的特点,需要用不同的方式去找数据;找数据的方式不同,底层的数据结构也就不同。
1. 一张压缩时间线
存储结构不是凭空出现的。每一种新结构,都对应一个具体的工程问题。
| 年份 | 事件 | 解决的问题 |
|---|---|---|
| 1970 | Bayer 与 McCreight 发表 B-tree 论文 | 磁盘上的点查与范围扫描 |
| 1979 | Comer 称 B-tree 为 “ubiquitous” | 关系数据库索引标准化 |
| 1996 | O’Neil 等发表 LSM-tree 论文 | 写密集场景下的随机写瓶颈 |
| 2005 | C-Store 论文发表 | 分析型查询读取大量无关列的问题 |
| 2010 | Dremel 论文发表 | 分布式列式查询 |
| 2016 | HNSW 算法论文发表 | 高维向量近似最近邻搜索 |
| 2020+ | RAG 推动向量检索普及 | 语义相似查询工业化 |
这条时间线说明一件事:新的存储结构不是为了取代旧结构,而是为了处理新的查询场景。
B-tree 没有消失。LSM-tree 没有统一所有数据库。列存也没有替代行存。向量索引更不是传统索引的终点。今天的 PostgreSQL 默认仍在使用 1970 年发明的 B-tree;2020 年的 RAG 系统在向量索引之外,仍然要依赖结构化过滤。
每一种结构服务于不同类型的查询:
| 查询是什么样子 | 典型结构 |
|---|---|
| 按主键找一条记录 | B-tree / Hash index |
| 找出某个范围内的记录 | B-tree |
| 高吞吐写入 | LSM-tree |
| 扫描大量行做聚合 | 列存 |
| 找包含某个词的文档 | 倒排索引 |
| 找某个地理范围内的点 | 多维索引 |
| 找语义相似的文本 | 向量索引 |
DDIA 第 4 章的价值,是把这些结构背后的权衡拆开看。
2. 索引和数据结构是两个层次
很多人会把”索引”和”数据结构”混在一起。但它们不是同一层概念。
| 维度 | 数据结构 | 索引 |
|---|---|---|
| 它是什么 | 组织数据的方式 | 帮助找数据的辅助结构 |
| 回答的问题 | 数据怎么组织 | 目标数据在哪里 |
| 所属层次 | 计算机科学基础概念 | 数据库或搜索系统中的工程概念 |
| 例子 | 数组、链表、哈希表、B-tree、跳表 | 主键索引、唯一索引、联合索引、倒排索引 |
| 关系 | 可以用来实现索引 | 通常由某种数据结构实现 |
直接的对应:B-tree 是数据结构;B-tree 索引是用 B-tree 实现的索引。
同一种索引在不同系统里可以用不同的数据结构实现。比如”主键索引”,PostgreSQL 用 B-tree 实现,RocksDB 用 LSM-tree 实现。索引的用途相同,实现的数据结构不同。
理解这一点之后,后面的 B-tree、LSM-tree、列存、倒排索引、向量索引就不是孤立知识点。它们都在回答同一个问题:
怎么针对某种类型的查询,设计一种更便宜的找数据方式。
3. B-tree:面向稳定点查和范围扫描
3.1 B-tree 解决的问题
1970 年前后的数据库系统面对几个约束:数据主要在磁盘上,内存远小于磁盘,查询既要按 key 找一条记录,也要扫描某个范围。
哈希表能快速点查,但不支持范围扫描。 排序数组支持范围扫描,但插入新数据要把后面所有元素挪位,代价随数据量线性增长。
B-tree 的目标是同时满足两件事:
- 找一条记录要快
- 找一个范围也要快
- 插入新数据的代价不能太高
它的做法是:把索引组织成一棵很矮的多叉树,每个节点对应一个磁盘页。
3.2 关键名词
| 名词 | 中文 | 含义 |
|---|---|---|
| Page | 页 | 磁盘上的固定大小块,常见 4 / 8 / 16 KiB |
| Root page | 根页 | 树的入口 |
| Internal page | 内部页 | 保存 key 范围和子页指针 |
| Leaf page | 叶子页 | 保存 key 和对应记录位置 |
| Branching factor | 分支因子 | 一个页能指向多少个子页 |
| Page split | 页分裂 | 页满后拆成两个页 |
| WAL | 预写日志 | 修改页之前先写日志,保证崩溃恢复 |
3.3 为什么 B-tree 查找快
这是理解 B-tree 最关键的一点。
回到最简单的文件做对比:1 亿条记录,文件 grep 要扫 5000 万行。
B-tree 的工作方式不同:从根页出发,根页里告诉你 key 应该去哪个子页找;进入子页,再告诉你去哪个孙子页;一直走到叶子页,找到记录。
关键是分支因子。一个页通常能放几百个子页指针——假设是 500 个。这意味着:
- 走 1 层,搜索范围从 1 亿缩到 1 亿 / 500 = 20 万
- 走 2 层,缩到 20 万 / 500 = 400
- 走 3 层,缩到 400 / 500 < 1,已经到叶子页了
所以 1 亿条记录,B-tree 只需要 3-4 次磁盘读取就能找到任何一条。
每往下走一层,搜索范围缩小到原来的几百分之一。这就是 B-tree 快的根本原因。
范围扫描也快:叶子页之间有指针连成一条链,找到范围起点的叶子页之后,顺着指针一路读下去就行。
3.4 B-tree 的写入流程
- 根据 key 找到目标叶子页
- 写 WAL
- 修改叶子页(直接在原位置覆盖)
- 如果页满了,把这个页拆成两个页
- 如果父页也因此满了,继续向上分裂
B-tree 维护的是一套可以原地更新的页结构。这带来两个特征:
- 读取路径稳定,每次查找都是从根到叶子的固定步数
- 写入时可能要修改磁盘上分散的页,可能产生随机 I/O
3.5 适合什么场景
B-tree 适合主键点查、范围扫描、读写比较均衡的事务系统、需要稳定延迟的系统。
SELECT * FROM orders WHERE order_id = 10001;
SELECT * FROM ordersWHERE created_at >= '2026-01-01' AND created_at < '2026-02-01';这两类查询的共同点是:查询条件可以沿着有序的 key 一步步缩小范围。
工程对应:PostgreSQL、MySQL InnoDB、SQLite、Oracle 默认的索引实现都是 B-tree 或其变种 B+tree。
3.6 B-tree 的限制
当写入量非常大时,每次写入可能要修改不同位置的页,磁盘随机写的成本会上升。
当查询只用少量列、却要扫描大量行时,B-tree 所在的行存布局也不占优势:
SELECT category, SUM(amount)FROM ordersWHERE created_at >= '2026-01-01'GROUP BY category;如果表有 100 列,但查询只用 3 列,行存会读取很多无关数据。这就引出了后面要讲的列存。在那之前,先看另一个针对写密集场景的方案。
4. LSM-tree:面向写密集场景
4.1 LSM-tree 解决的问题
B-tree 在写密集场景下会遇到瓶颈:每次写入都要找到目标页修改它,这些页可能分散在磁盘的不同位置,导致大量随机写。机械硬盘的随机写每秒只能做几百次。
1996 年前后,互联网网站日志、搜索引擎索引、大规模时序数据相继出现,写入频率开始远高于读取频率。B-tree 不再够用。
LSM-tree(Log-Structured Merge-tree)的目标是:让所有写入都变成顺序写。
顺序写为什么重要?因为顺序写比随机写快很多。在机械硬盘上差几百倍,在 SSD 上也快好几倍。如果能把写入都变成顺序的,写入吞吐就能提升一个数量级。
4.2 关键名词
| 名词 | 中文 | 含义 |
|---|---|---|
| Memtable | 内存表 | 内存中的有序结构(红黑树或跳表) |
| SSTable | Sorted String Table | 磁盘上的有序文件,写完后不再修改 |
| WAL | 预写日志 | 防止 memtable 中的数据因崩溃丢失 |
| Compaction | 合并 | 后台合并多个 SSTable |
| Tombstone | 删除标记 | 删除操作写入的特殊记录 |
| Bloom filter | 布隆过滤器 | 快速判断 key 是否一定不在某文件中 |
4.3 为什么 LSM-tree 写入快
LSM-tree 的核心设计是:写入不直接落盘,先写到内存。
一次写入做两件事:
- 把这条记录追加到 WAL 文件末尾(顺序写,很快)
- 把这条记录插入到内存中的 memtable(纯内存操作,几纳秒)
用户能感知到的写入延迟,就是这两步加起来的时间——大约一次磁盘顺序写加一次内存操作。没有随机寻页,也不需要修改任何已有数据。
memtable 写满之后(一般几 MB 到几十 MB),系统把整个 memtable 一次性顺序写到磁盘,形成一个新的 SSTable 文件。这是一次大块的顺序写,效率很高。
所以从用户角度看,每次写入都很快;从磁盘角度看,所有写入都是顺序的,没有随机写。
4.4 为什么 LSM-tree 读取也不算慢
读取看起来麻烦:数据散落在 memtable 和很多 SSTable 文件里,最坏情况要查所有文件。但实际上有两个机制让读取依然可控。
第一,每个 SSTable 内部是排好序的。
排序之后,单个 SSTable 内查找一个 key 是 O(log n),和 B-tree 一样快。SSTable 文件内部还有稀疏索引,能快速定位到 key 所在的数据块。
第二,Bloom filter 帮你跳过大部分文件。
Bloom filter 是一个很小的位图(每个 key 占大约 10 个 bit),可以快速回答”这个 key 一定不在这个 SSTable 里吗”。如果它说”一定不在”,就跳过这个文件。如果它说”可能在”,再去读文件。
实践中 Bloom filter 的误判率可以做到 1% 以下。也就是说,查 100 个 SSTable,平均只需要真正读 1 个左右。
所以一次读取大概是:
- 查 memtable(内存操作)
- 对每个 SSTable 用 Bloom filter 判断(很快)
- 在 1 - 2 个 SSTable 里实际查找(每次 O(log n))
整体仍然在毫秒级。比 B-tree 慢,但不会慢一个数量级。
4.5 LSM-tree 的写入流程
- 写 WAL
- 写入 memtable
- memtable 达到阈值后冻结
- 冻结的 memtable 顺序写成 SSTable
- 后台合并多个 SSTable
修改一个 key,是写入一个新版本,旧版本仍然存在。 删除一个 key,是写入一个 tombstone,等后续合并时真正清理。
4.6 LSM-tree 的代价
| 代价 | 含义 |
|---|---|
| 一次读取可能查多个文件 | 数据散在多个 SSTable 里,需要逐个查(Bloom filter 缓解) |
| 一份数据被反复写多次 | 同一条记录可能在多次合并中被反复重写 |
| 旧版本占用额外空间 | 删除和修改不会立即清理,等合并时才真正生效 |
| 后台合并影响延迟 | 合并是 IO 密集任务,可能影响前台读写 |
LSM-tree 不是”更先进的 B-tree”。更准确地说:B-tree 维护一套可原地更新的页结构;LSM-tree 维护一组不断合并的不可变文件。它们的核心差异是写入路径不同。
4.7 适合什么场景
LSM-tree 适合写入量大、追加型数据、日志型数据、时序型数据、可以接受后台合并成本的系统。
不一定适合:强依赖稳定低延迟点查的场景;大量更新和删除、但合并跟不上的场景;对存储空间非常敏感的场景。
工程对应:RocksDB 是 LSM-tree 的代表实现,由 Facebook 在 2012 年从 LevelDB fork 而来。
5. B-tree 与 LSM-tree 对照
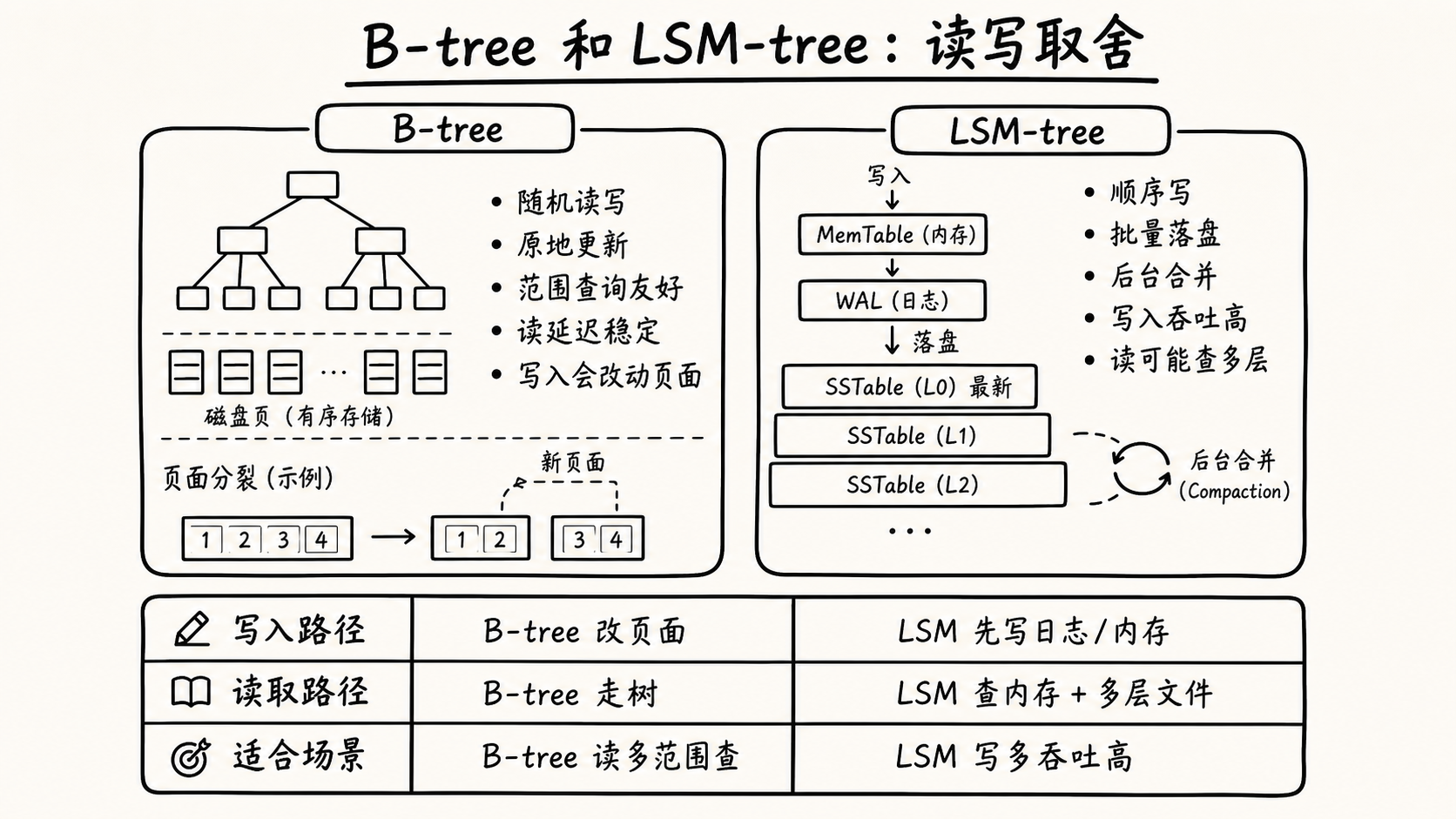
B-tree 和 LSM-tree 解决的是同一类问题:如何在磁盘上维护一个按 key 可查询的数据集合。但它们选择了不同的写入路径。
| 对比项 | B-tree | LSM-tree |
|---|---|---|
| 核心机制 | 维护磁盘页结构 | 维护内存表和不可变文件 |
| 写入方式 | 定位目标页后原地修改 | 先写内存,再顺序落盘 |
| 磁盘文件 | 页会被反复修改 | 文件写完后通常不再修改 |
| 读取路径 | 沿树查找,路径较稳定 | 可能查 memtable 和多个 SSTable |
| 后台任务 | 页分裂、页回收 | 合并、tombstone 清理 |
| 主要优势 | 读延迟稳定,范围扫描自然 | 写吞吐高,磁盘只做顺序写 |
| 主要代价 | 随机写、页分裂 | 读取要查多个文件、空间占用更大 |
| 适合场景 | 读写均衡、事务系统 | 写密集、追加型系统 |
三个判断场景:
订单系统:读写都重要,点查频繁,延迟要稳定。选 B-tree。
用户行为日志:写入量远高于读取,数据多为追加。选 LSM-tree。
时间范围查询:如果数据按时间写入,LSM-tree 或按时间组织的存储结构都可能有效。关键不是引擎名字,而是数据是否能按查询条件形成有序排列。
6. 列存:面向大规模扫描
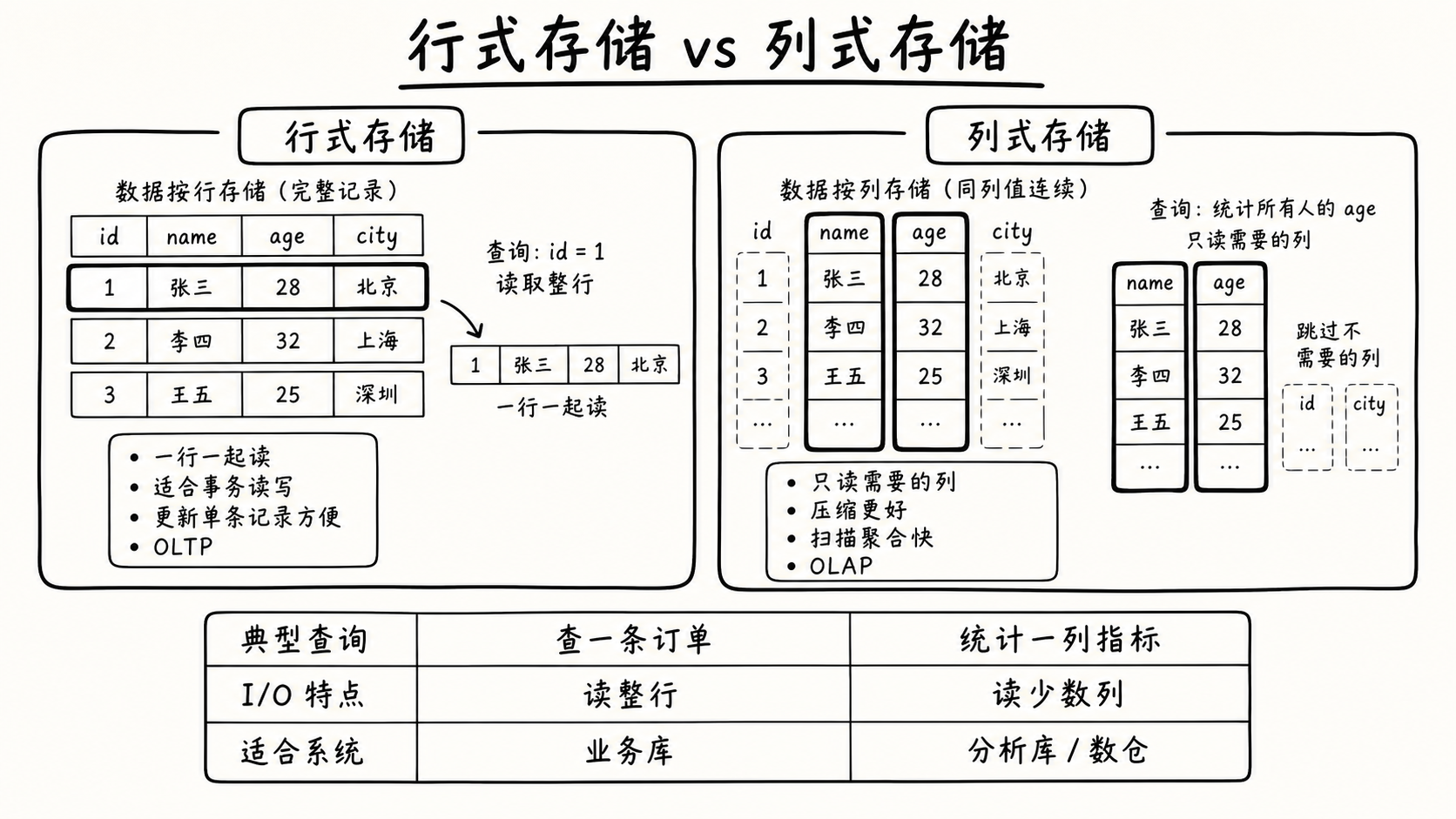
6.1 行存的问题
OLTP 引擎以行为单位组织数据。但分析查询经常是这种样子:
SELECT category, SUM(qty) FROM fact_salesWHERE year = 2024 GROUP BY category;表有 100 列、10 亿行,查询只用 3 列。行存必须把每行的 100 列都从磁盘读上来,丢弃 97 列。
6.2 列存的核心思想
把同一列的数据连续放在一起,查询只读取需要的列。带来四个好处:
- 减少 I/O:只读涉及的列
- 提高压缩率:同一列里数据类型相同、值分布相似,更容易压缩
- 适合向量化执行:一次处理一批列值,而不是一行一行解释
- 适合统计信息裁剪:每个数据块保存 min / max 等元数据,可以跳过无关数据块
6.3 一个常见误解:列存不是”一个字段一个文件”
Parquet 通常仍是单个文件。文件内部分成多个 row group,每个 row group 内部再按列组织:
一个 Parquet 文件├── Row Group 1│ ├── Column chunk: user_id│ ├── Column chunk: category│ └── Column chunk: amount├── Row Group 2│ └── ...└── Metadata(每列的 min / max / null count / offset)查询引擎根据 metadata 找到需要读取的列块位置。如果查询只用 category 和 amount,就不读取其他列的字节范围。
6.4 排序对列存的影响
Parquet / ORC 本身不会自动排序。是否排序由写入任务决定。
未排序时,每个 row group 的 min / max 范围可能覆盖整列,查询无法跳过任何 row group。按过滤列排序后,row group 的 min / max 变窄,查询可以跳过大部分数据。
ClickHouse 的 ORDER BY 不是普通索引,它决定数据在磁盘上的物理排列顺序。这是建表时最重要的设计决策之一。
工程对应:文件格式有 Parquet、ORC、Lance;数仓产品有 ClickHouse、Snowflake、BigQuery;查询引擎有 DuckDB、Trino、Spark SQL。
7. 物化视图和数据立方体
除了索引,数据库还可以通过提前计算来加速查询。
7.1 物化视图
普通视图只是保存 SQL,每次查询展开重跑:
CREATE VIEW revenue_by_day ASSELECT day, SUM(amount) FROM orders GROUP BY day;物化视图把查询结果真正存下来:
day revenue2026-01-01 1000002026-01-02 120000代价:占用额外存储;底表变化时需要刷新;刷新可能有延迟;维护逻辑更复杂。
物化视图是一个权衡:用更多空间和更新成本,换更快的读取。
工程对应:ADS 层汇总表(手动维护)、ClickHouse MATERIALIZED VIEW(自动维护)、Materialize(增量物化)。
7.2 数据立方体
数据立方体是更进一步的预聚合。例如销售数据有日期、地区、类目三个维度,可以提前计算所有维度组合的聚合结果。查询时不扫明细表,直接读预聚合结果。
问题是:维度越多,组合数量增长越快。所以数据立方体适合查询模式稳定、维度数量可控的场景。
在现代列存系统里,明细扫描速度已经很快。因此 cube 的价值不再是默认选择,而是特定场景下的加速结构。
工程对应:Kylin、Druid、SQL 的 GROUP BY CUBE 语法。
8. 多维、倒排、向量索引
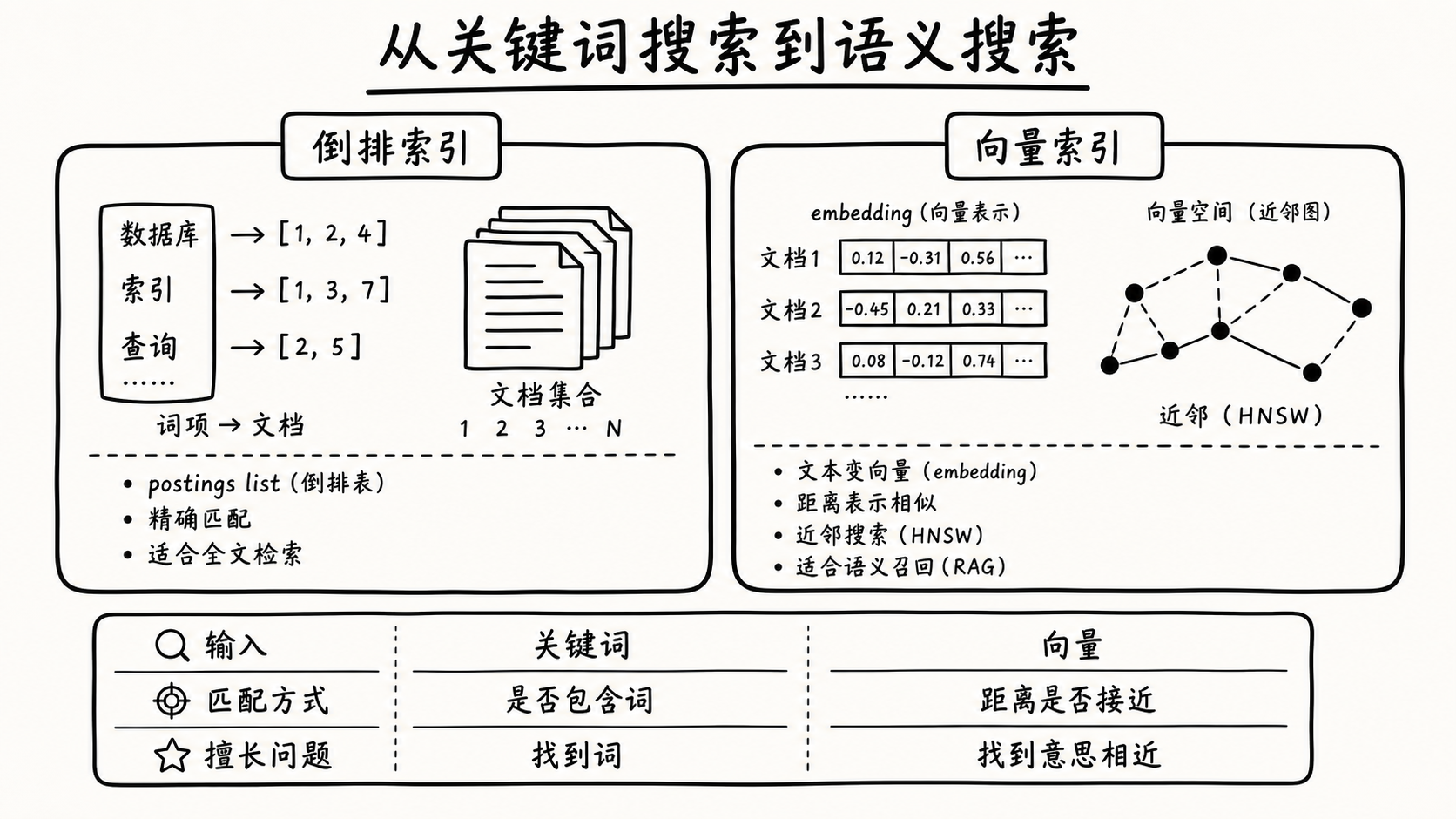
前面的结构主要处理结构化数据。但现实查询还有更多类型:地图范围、关键词、语义相似。
| 查询类型 | 查询特点 | 典型结构 |
|---|---|---|
| 地理位置查询 | 二维或多维范围 | R-tree / 空间填充曲线 |
| 全文搜索 | 大量词中匹配少量 | 倒排索引 |
| 向量搜索 | 高维空间找近邻 | HNSW / IVF / Flat |
8.1 多维索引
前面讲的索引都是按一个维度排序的:B-tree 把数据按 key 从小到大排好,所以”找一个范围”才快。但地理查询天然是两个维度的——比如找出某个矩形范围内的所有餐厅:
SELECT * FROM restaurantsWHERE lat BETWEEN 30.20 AND 30.30 -- 纬度 AND lng BETWEEN 120.10 AND 120.20; -- 经度直觉上,给 lat、lng 两列建一个联合索引(把两列拼在一起排序的 B-tree)应该能解决。但它不行,原因在于联合索引只是先按 lat 排、lat 相同再按 lng 排,本质还是一条按 lat 排好的长队。
用电话簿打个比方:电话簿先按姓排,姓相同再按名排。要找”姓在 A–M 之间”很快,因为这是连续的一段。但要找”姓在 A–M 之间且名在 A–M 之间”,你只能先翻到姓 A–M 那一大段,再在里面一个个挑名字符合的——符合的人散落在这一大段的各个角落,并不连续。
(lat, lng) 索引就是这样:它能快速圈出 lat 在 30.20–30.30 的所有点,但这些点的 lng 什么值都有,还得逐个过滤。维度一多,一维排序就照顾不过来了。解决办法有两类。
第一类:R-tree——直接用矩形把点分组。
R-tree 不再把点排成一条队,而是把位置相近的点圈进一个矩形框(也叫 bounding box,外接矩形),再把相近的矩形框圈进更大的框,一层层套起来形成一棵树。查询时,只要你的查询范围和某个框不相交,框里所有点就整体跳过,连看都不用看。这样二维范围查询也能像 B-tree 那样层层缩小搜索范围。PostgreSQL 的地理空间扩展 PostGIS 就用这种结构。
第二类:空间填充曲线——把二维”压扁”成一维。
如果还是想用现成的一维 B-tree,就得想办法把二维坐标变成一个一维的数,而且要尽量做到二维上挨得近的点,算出来的一维数也挨得近。空间填充曲线就是干这个的:想象一条蜿蜒的线,按某种固定顺序穿过地图上每一个格子,一个点落在这条线的第几步,就是它的一维编号;挨得近的点编号通常也挨得近,于是又能用普通的有序索引来查。常见的画法有 Z-order 曲线和 Hilbert 曲线。Delta Lake 的 ZORDER BY 就是用这个思想,把相关的数据在文件里聚到一起,让过滤查询能跳过大量无关文件。
8.2 倒排索引
普通索引:文档 ID → 文档内容。 倒排索引:词 → 包含这个词的文档列表。
apple → [doc1, doc3, doc8]red → [doc1, doc8]查询 red AND apple 等于两个 posting list 取交集。
倒排索引适合”一篇文档只包含整个词表里的少量词”这种数据——每个词都是一个维度,整个词表有几万个维度,但每篇文档只在其中很小一部分维度上有值。
在抽象层面,倒排索引和列存的 bitmap encoding 接近:都是”某个值 → 一组行号 / 文档号”。但全文搜索还涉及分词、词频、相关性排序、BM25 等额外语义,不能完全等同。
8.3 向量索引
倒排索引依赖关键词重合。但用户搜”取消订阅”,文档标题”关闭账户”——两者没有共享词,但语义接近。
向量索引用 embedding 模型把文本转成高维浮点向量,在向量空间里查最近邻。常见方式:
- Flat:暴力扫描所有向量,精确但慢
- IVF:先聚类,查询时只搜索最相关的几个聚类
- HNSW:分层图结构,查询复杂度近似 O(log n)
后两者用一点精度换数量级的速度,结果可能不是最精确的最近邻,但足够近。
向量索引不是传统索引的替代品,而是新出现的另一种找数据方式。在 RAG 系统里,它通常和结构化过滤、关键词召回、rerank 一起使用。
9. 选型权衡
9.1 没有免费的结构
每种结构都在三个目标之间做权衡:读性能、写性能、空间占用。这就是 DDIA 引用的 RUM conjecture(Read-Update-Memory)。
| 结构 | 优化目标 | 牺牲项 |
|---|---|---|
| B-tree | 稳定点查、范围扫描 | 随机写、页维护成本 |
| LSM-tree | 写吞吐 | 一次读要查多个文件、占用更多空间 |
| 列存 | 聚合扫描、压缩 | 单行更新复杂 |
| 物化视图 | 查询速度 | 刷新成本、额外空间 |
| 数据立方体 | 多维聚合速度 | 维度组合膨胀 |
| 倒排索引 | 关键词查找 | 索引空间、维护成本 |
| 向量索引 | 语义相似查找 | 精度、内存、构建成本 |
每一种”读得更快”,都要在别的地方付费——写入更慢、空间更大、后台维护更复杂、结果不再精确、数据刷新有延迟。
9.2 选型启示
存储引擎选型不能只问”哪个更快”,应该问”它让哪类查询更快、把成本转移到了哪里”。
选型前先看清楚自己的查询是什么样子:是按主键找一条记录,还是扫描某个范围?读多还是写多?查少量行,还是扫描大量行?是结构化过滤,还是全文搜索?精确匹配,还是语义相似?是否需要每次查询都很稳定?
不同答案指向不同结构:
| 查询是什么样子 | 更可能需要 |
|---|---|
| 按主键找一条记录 | B-tree / Hash index |
| 找一个范围内的记录 | B-tree / 排序存储 |
| 写入量大 | LSM-tree |
| 扫描大量行做聚合 | 列存 |
| 找包含某个词的文档 | 倒排索引 |
| 找地理范围内的点 | 多维索引 |
| 找语义相似的内容 | 向量索引 |
| 同样的聚合反复跑 | 物化视图 / 预聚合 |
三个具体提醒:
- Parquet / ORC 默认不排序——排序是写入时要做的事,不是格式自动完成的
- ClickHouse 的 ORDER BY 是物理排列——决定数据在磁盘上的组织顺序
- 倒排索引和列存的 bitmap 在抽象层面相似——理解一个有助于理解另一个
10. 收尾
DDIA 第 4 章讲的不是某一种数据库,也不是某一种索引。它讲的是:数据库如何根据不同类型的查询,设计不同的找数据方式。
这些结构没有谁彻底取代谁。它们只是把成本放在了不同地方:有的牺牲写入换读取稳定,有的牺牲读取稳定换写入吞吐,有的牺牲空间换查询速度,有的牺牲精度换近似搜索速度。
工程选型的第一步不是比较产品名,而是看清楚自己要回答的查询是什么样子。