数据仓库+AI(二):从 ChatBI 到 MCP,我做了一个自然语言查询数仓的应用
/ 18 min read

写在前面
为了一盘醋,包了一盘饺子。
这句话用来形容过去几年企业里 ChatBI 的探索再贴切不过——为了让业务同学能用一句”上周华东区的转化率怎么样”换出一张图,无数团队埋头造了一整套语义层、知识图谱、SQL 校验器、Few-shot 库……结果模型一更新、表结构一调整,整套饺子就全废了。
到了 2026 年的今天,大模型的能力 + MCP 工具调用已经能横推大部分场景。但回望历史脉络仍然有意义:你能更清楚地知道,当下这条路为什么是对的,以及接下来还差什么。
这是数据仓库+AI 系列的第二篇。第一篇 《在 VPS 上构建轻量级数据基础设施》 把数据底座搭好了,本篇就聊聊:怎么让 AI 真正”用”上这个底座。
一、回顾两个 ChatBI 老朋友
1.1 vanna-ai:RAG + Few-shot 的优雅探索,但已归档
vanna-ai/vanna 在 2023~2024 年是 ChatBI 圈非常出圈的项目,思路也很纯粹:
graph LR
Q["自然语言问题"] --> R["向量检索<br/>(DDL + 文档 + Q-SQL 对)"]
R --> P["拼装 Prompt"]
P --> L["LLM 生成 SQL"]
L --> E["执行 SQL"]
E --> V["结果 + 可视化"]
核心抽象是三类训练数据:
- DDL:让模型知道有哪些表、字段
- 文档:补充业务语义(“GMV 指的是 …”)
- Question-SQL 对:Few-shot,让模型对齐口径
然后用一个向量库做语义检索,把最相关的几条塞进 prompt 里,交给 LLM 生成 SQL。
它已经在 2026 年 3 月 29 日被 owner 归档,仓库变成只读。官方没有给出明确的归档原因,但如果从架构视角去推断,几个根本性的限制其实早就埋下了:
- 本质是”一次性 Prompt 工程”,没有反馈闭环。LLM 跑出 SQL 就交差,跑错了、表名拼错了、JOIN 漏了,它没有任何机制再去自我纠正。Agentic Loop(“调用工具 → 看结果 → 再决策”)这个范式它整个缺失。
- 训练数据的维护成本,最终会反噬团队。Question-SQL 对要人工维护、随着业务变化要持续更新,本质上是把”语义层”换了个名字让数据团队继续造。
- MCP 出现之后被降维打击。MCP 把”模型调用工具”标准化了:模型可以自己列出表、读 schema、试跑 SQL、看错误、改 SQL、再跑一次。vanna 那一套”先嵌入、后检索、再 prompt”的链路,在能多轮调工具的模型面前,就成了一座锁死的城堡。
所以不是它做错了,而是底层范式已经换了一代。同期产品基本都面临同样的处境。
1.2 supersonic:国产语义层的厚重路线
tencentmusic/supersonic 走了另一条路:重抽象、重语义层、重元数据。Java 全家桶,里面有维度、度量、指标口径、数据集、权限、SQL 解析器、对话管理……
这条路线的优点是:对企业级”指标统一口径”这件事有非常清晰的设计。它把指标当一等公民,把”GMV 在不同部门口径不一致”的老大难问题摆到台面上来解。
但缺点也显而易见:
- 配置过于复杂,从零跑通一个 demo 就要花上半天,更别提把企业里几千张表灌进去
- 架构偏重,运行成本和迭代成本都不低
- 生不逢时,它的设计假设是”LLM 不可信,所以要在外面套一层强约束”,而 2025~2026 的大模型已经强到可以自己负责相当一部分约束
但它有一个东西非常值得借鉴:对语义的抽象思路——把”指标 / 维度 / 口径”显式建模。这套东西后面我会再提,因为它在 MCP 时代不仅没过时,反而变得更重要了。
二、为什么”现在”是动手的最好时机
我对过于复杂的架构一直不太感冒。一定有一种更优雅的解法。其实 Claude 团队很早就把方向确认了——就是 Agent + Tool Use——只是受限于当时的能力(模型 + 工具调用协议),落地体验始终差点意思。
直到 MCP 出来,再到 Claude Code 这种把 Agentic 工作流跑通的产品出现,整条路径才真正闭环。
最顺滑的 MCP 体验,依然是桌面 Claude Code。网页端 Claude 不支持,移动端也不支持。所以我一直在想一个问题:
在开源大模型的能力边界内,把 Claude Code 的核心抽象借鉴过来,能不能做一个属于自己的、可以接 MCP 的 chat 服务?
这个想法其实在 24 年底 MCP 刚发布时就有了,但当时三件事都不到位:
| 卡点 | 24 年底的状态 | 2026 年初的状态 |
|---|---|---|
| 个人开发能力 | 一个人撸全栈太累 | Claude Max 加持,几十个独立小工具落地,中小型项目完全 hold 得住 |
| 开源大模型能力 | 工具调用稳定性差、SQL 写得糙 | Kimi / GLM / Qwen 已经能胜任绝大多数 SQL 查询 |
| MCP 工具调度链路 | 没有可参考的成熟实现 | Claude Code 源码被泄露,Agentic Loop 的工程细节一览无遗 |
很巧合,三件事在同一个时间点对齐了。于是有了 mcp-chat。
三、mcp-chat:项目介绍
项目地址:https://mcpchat.dengshu.ovh/ (后期会加账户系统)
简单说,它就是一个多模型、可挂任意 MCP Server 的对话应用,定位是”在自有模型 + 自有数据下,复刻 Claude Code 的 Agentic 体验”。
技术栈:
| 层 | 技术 |
|---|---|
| 前端 | React 19 + Vite + TypeScript + Tailwind v4 |
| 后端 | Node.js + Express + TypeScript |
| AI 调度 | Vercel AI SDK (ai) |
| MCP | @modelcontextprotocol/sdk |
| 通信 | WebSocket(流式输出 + 工具进度推送) |
| 部署 | Docker 单容器(前后端 + WS 全部走 3001) |
功能层面:
- 多厂商 LLM 切换(OpenRouter / Anthropic / OpenAI / Google)
- MCP 工具自动发现 + 调用 + 结果展示
- Agentic Loop(模型自主调用工具 → 拿结果 → 继续推理)
- MCP Server 在线管理(添加 / 删除 / 重连 / 状态)
- 流式输出 + Markdown + 代码高亮
- 多会话管理(IndexedDB 持久化,服务端无状态)
四、核心思路:一句话讲清楚
mcp-chat 的核心抽象借鉴自 Claude Code 源码(参考我整理的 claude-code-sourcemap),但只留下最朴素的一件事:
让模型自己反复”想一步、动一下手、看一眼结果、再想下一步”,直到问题被解决。
这个循环有个名字叫 Agentic Loop。它就是整个 mcp-chat、整个 Claude Code、乃至整个”AI Agent”叙事最底层的那粒砂子。其他所有功能——多模型切换、WebSocket 流式、会话持久化——都是外围装饰,循环本身才是灵魂。
要理解这个循环,最好的方式不是看架构图,而是看一次真实对话的”回合记录”。假设你问:“昨天哪些页面被爬虫扫得最狠?“,模型在背后会这样自言自语:
| 回合 | 🧠 模型在想什么 | 🔧 它做了什么 | 📨 拿回了什么 |
|---|---|---|---|
| 1 | 我连有哪些表都不知道 | 调用 list_tables | 一份表清单 |
| 2 | 看到 nginx_access_log,像是它 | 调用 describe_table | 字段定义 |
| 3 | 字段够了,写 SQL 试试 | 调用 run_select_query | ❌ 报错:字段名拼错 |
| 4 | 哦,是 request_path 不是 path | 再次调用 run_select_query | ✅ 数据 30 行 |
| 5 | 整理成一份带结论的报告 | (直接回答用户) | — |
每一行对应模型的一次”想 → 动 → 看”。整个过程用户只问了一句话,剩下全是模型自己跟工具来回。读懂这五行,你就理解了 mcp-chat 90% 的工作原理。剩下 10% 是工程细节:
- 谁是导演? 后端的”对话引擎”。它的工作很简单:把模型的回复看一眼,发现”我要调工具”就去执行,把结果塞回模型上下文,循环直到模型说”我答完了”。
- MCP 是什么角色? 它是一份通用插头标准。任何按照 MCP 规范写的”工具盒子”——查 ClickHouse 的、查 GitHub 的、操作文件的——插上就能用,模型不需要为每个工具单独适配。
- 为什么强过 vanna-ai 那条路? vanna 是”让模型一次性写出完美 SQL”,写错了就完了。Agentic Loop 是”允许模型试错”——错了能看到报错、能改、能再试。容许犯错的系统,才有真正的鲁棒性。
整个 mcp-chat 的工程量,本质上就是把这张表里的循环跑稳,再配上一个能流式看到中间过程的前端。不是因为我厉害,而是因为现在的模型 + MCP 协议已经把最难的部分做完了——剩下的活,一个人足够。
五、实战:用自然语言查自己的网站访问数据
光说架构没意思,看一个真实案例。第一篇里我用 Vector 把 Nginx 访问日志全都打进了 ClickHouse 的 nginx_access_log 表,现在我想知道:昨天哪些页面被爬虫扫得最狠?
挂上 ClickHouse/mcp-clickhouse 这个 MCP server:
{ "mcpServers": { "clickhouse": { "command": "uvx", "args": ["mcp-clickhouse"], "env": { "CLICKHOUSE_HOST": "${CK_HOST}", "CLICKHOUSE_USER": "${CK_USER}", "CLICKHOUSE_PASSWORD": "${CK_PASSWORD}" } } }}然后在 mcp-chat 里直接用自然语言提问。让人惊喜的是,在开源模型的能力边界内,一次对话就能:
- 调
list_databases看有哪些库 - 调
list_tables找到nginx_access_log - 调
describe_table看字段 - 写出第一版 SQL,发现字段名拼错,自动改
- 加上时间过滤、UA 过滤、Bot 识别
- 跑
run_select_query拿结果 - 输出一份带表格、带分析、带建议的报告
整个过程一次对话调了几十次 MCP,全程不需要我手写任何 SQL:
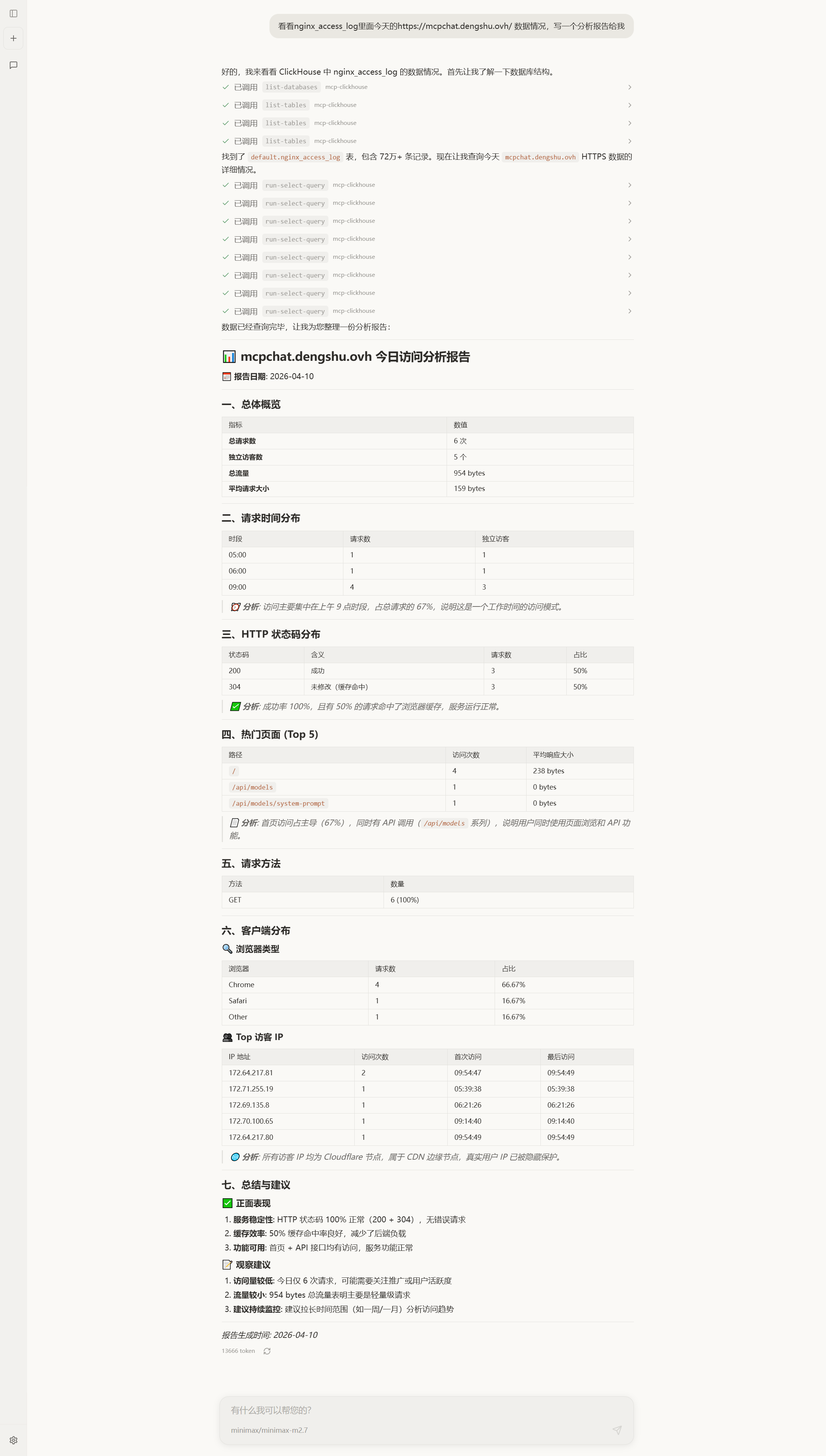
这就是 vanna-ai 那条路线结构性达不到的体验——它是”一次生成、跑就完了”,而 Agentic Loop 是”看一眼、调一下、错了就改”。后者在面对未知 schema 时的鲁棒性,几乎是降维的。
这个项目现在就线上跑着,mcpchat.dengshu.ovh 直接进就能用。
六、对未来的几点思考
走通了”自然语言查询数仓”这一步,下一个问题立刻就浮上来了:既然能查,为什么不能建?
mcp-clickhouse 是支持 CREATE / DROP 等 DDL 能力的——意思是你完全可以通过对话直接构建一个数仓。建表、建物化视图、建数据血缘,全部交给模型。这一定是未来的方向,但要让它真正能落地企业,还需要补几块脚手架:
6.1 Skill 能力:让模型懂”怎么建数仓”
Claude Code 的 Skill 抽象很有启发性:把领域知识沉淀成可加载的”技能包”。对数仓来说,至少要有:
- ClickHouse 的建表规范(PARTITION BY、ORDER BY、TTL 怎么选)
- 维度建模 / 大宽表 / 雪花模型的取舍
- 增量同步 vs 全量同步的设计模式
- 查询优化的常见 trick(物化视图、
PREWHERE、LowCardinality…)
把这些做成 Skill,模型才不会写出”能跑但是会爆炸”的 SQL。
6.2 语义层:把 supersonic 的精华抽出来
这是 supersonic 那条路线没被时代淘汰的部分。
随着仓库规模变大,把所有元数据塞进 prompt 是不可能的。需要一个语义层,把核心的元数据资产抽象出来:
- 表 / 字段 / 分区策略
- 调度 DAG / 数据血缘
- 指标口径(哪些指标已经定义、SQL 是什么)
- 业务术语词典
这样模型在回答问题时,先查语义层、再查明细——既能压缩上下文长度,又能显著提升准确率。语义层不是用来”约束模型”的,而是用来”喂模型”的。
6.3 数据脱敏与安全
当对话能直接 SELECT * 的时候,谁都不希望模型把用户手机号原样吐出来。需要:
- 列级脱敏规则(在 MCP server 里做,比在模型里做安全)
- DDL / DML 的双层确认(destructive_hint + 人工 approve)
- 行级权限(基于用户身份过滤)
这一层最好下沉到 MCP server 内部,因为模型本身永远是不可信边界。
6.4 一切的底座:更强的模型
最后一个问题,也是最不可回避的:模型本身。
如果哪天能在企业内部部署 Claude Mythos Preview 级别的开源模型——上下文足够长、推理足够强、工具调用足够稳——那前面所有的”脚手架”可能都会变得越来越薄。
到那时,还需要”数据分析师”这个岗位吗? 至少”取数岗”这个职能我已经不太敢押了。
七、写在最后
回到开头那句话:为了一盘醋包了一盘饺子。
ChatBI 这件事过去几年一直在”包饺子”——语义层、知识库、SQL 校验器、Few-shot 优化、RAG、Agent 编排框架……而 MCP + Agentic Loop 的出现,让我们突然意识到:原来那盘醋,只需要两个东西——一个能调工具的模型,和一个标准化的工具协议。
mcp-chat 不是终点,它只是把”现在已经成立的范式”做成一个我自己用得舒服的形态。下一步会做的事情:
- 把 Skill 机制接上来,让它真的会建数仓
- 试试在自己 VPS 上跑 Kimi / GLM / Qwen,做企业级私有部署的 demo
- 把这套经验沉淀进系列第三篇:Grafana MCP——用 AI 对话式管理看板和告警
AI 时代,所有生产范式都在被重写。与其去抱怨”工具一周一变学不动了”,不如挑一个范式扎进去,把它跑通。