Everything changes and nothing stands still. ——Heraclitus
0. 一次「明明没动下游」的事故
有一次上游团队给一个 Kafka topic 的消息加了个字段——就加了个字段,谁都觉得这是个安全操作。结果我们一个一直在线、那阵子没重新部署的老消费者,把这条消息读进来、改了改、又写回另一个 topic,那个新字段就这么没了。下游再去用,发现数据「缺了一块」,排查了大半天,最后定位到的不是哪段代码写错了,而是:老代码不认识新字段,反序列化的时候直接把它丢了。
这件事我后来一直记着,因为它违反直觉:我们明明什么都没改,下游却坏了。DDIA 第 5 章讲的就是这类问题,而且开篇就把根源点破了——
应用会一直变。加功能、改需求、调业务,几乎每次都伴随存储的数据格式跟着变。但代码和数据的「变」是两种速度:
- 代码可以几分钟内全量替换。 服务端做滚动升级(rolling upgrade),一批一批换节点;客户端更惨,你根本管不了用户什么时候更新 App。
- 数据不会跟着替换。 五年前写进库里的那行记录,今天还是当年那个格式躺在那儿,除非你专门去重写它。
Kleppmann 把后面这句总结成一句我很喜欢的话:data outlives code,数据比代码活得久。
这句话是整章的主线。正因为你永远没法「一瞬间把所有东西都升级到新版本」,所以在任何一个时间点,系统里都同时跑着新旧两版代码、躺着新旧两种数据格式。要让它继续正常运转,你需要的不是「升级」,而是让新旧能共存。
1. 真正的需求:两个方向的兼容
新旧共存,意味着你要同时维护两个方向的兼容性。这两个词我以前老记混,这次彻底掰清楚:
| 兼容性 | 含义 | 谁迁就谁 |
|---|---|---|
| 向后兼容(backward) | 新代码能读旧代码写的数据 | 新版迁就老数据 |
| 向前兼容(forward) | 旧代码能读新代码写的数据 | 老版迁就新数据 |
记忆法:站在「现在」往回看(backward)是读历史数据,往前看(forward)是读未来才会出现的数据。
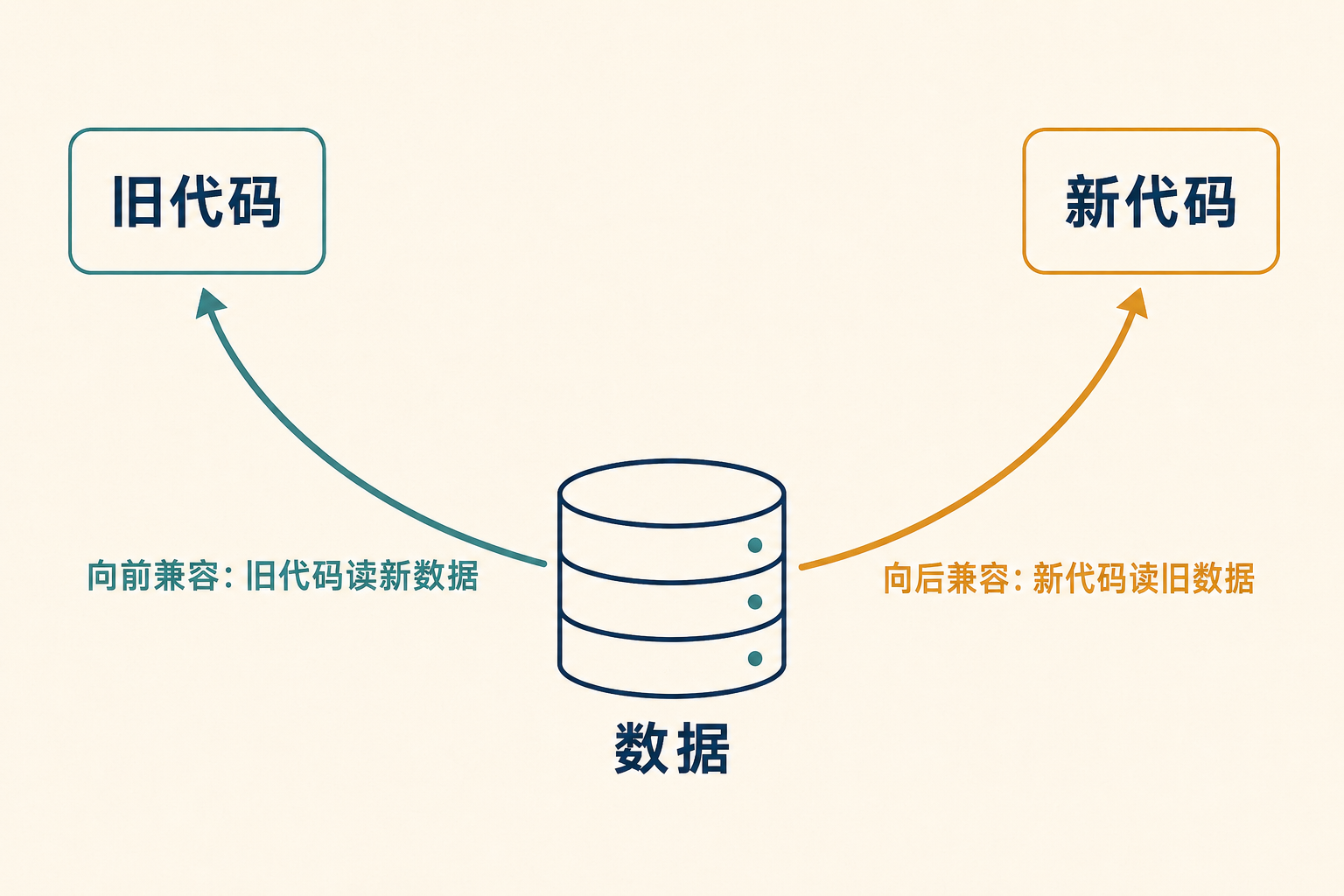
向后兼容通常不难。 你写新代码的时候,旧格式长什么样是已知的,大不了留一段老逻辑专门读老数据。
向前兼容才是真正的坑。 它要求旧代码去容忍它根本不认识的东西——新版加的字段,老版得能视而不见,而且不能误伤。开篇那个事故就是向前兼容没做好:老代码不但没忽略新字段,还在「读出来→改→写回去」的过程中把它弄丢了。
新版写入:{ name, age, email(新加的) } │ ▼老版读取:解析成只有 { name, age } 的对象 ← email 在这一步被丢掉 │ 改 age ▼老版写回:{ name, age } ← email 永久消失这就是 DDIA 里 Figure 5-1 描述的场景:只要中间经手的旧代码不能完整保留未知字段,数据就会在一次普通的读改写里悄悄丢失。 后面讲编码格式时,判断一个格式好不好用,很大程度上就是看它处理这种情况的能力。
顺带把 API 那一档也理清楚:老客户端调新服务,需要请求向后兼容、响应向前兼容;新客户端调老服务,则反过来。本质都是同一回事——通信的两端版本可能不一致。
2. 编码到底在干嘛
程序里的数据有两种存在形态:
- 在内存里:数据以各种「数据结构」的形式存在——对象、结构体(把一组字段打包在一起,比如一个用户有「姓名」「年龄」两个字段)、列表、哈希表、树等等。这些结构内部到处是指针:指针就是一个内存地址,相当于「那块数据存在内存的哪个位置」的门牌号,让一个结构能直接引用到另一个结构。这种形态是为 CPU 快速访问设计的。
- 在文件里 / 网络上:数据必须是一段自包含的字节序列(一串首尾相连、不依赖任何外部信息就能读懂的字节)。指针在这里毫无意义——内存地址是本进程私有的,换个进程、换台机器,那个「门牌号」根本指不到同一个东西。
从内存形态转成字节序列叫编码(encoding / 序列化 / marshalling),反过来叫解码(decoding / 解析 / 反序列化)。这一章剩下的内容,全是在讨论「这一步怎么做,以及不同做法在演化时的代价」。
书里专门吐槽了一句术语混乱:serialization 这个词在事务那一章(第 8 章)是完全另一个意思,所以全书统一用 encoding。
别用语言内置的序列化
Java 的 Serializable、Python 的 pickle、Ruby 的 Marshal——用起来确实爽,一行代码存取对象。但它们有几个深坑,基本判了「别用于临时用途之外的任何场景」的死刑:
- 绑死语言:用 pickle 存的数据,换个语言基本读不了。等于把自己锁死在当前技术栈上。
- 安全灾难:反序列化要能实例化任意类。攻击者只要能让你的程序解码一段它构造的字节,往往就能远程执行代码(
CWE-502这类漏洞的源头)。 - 版本兼容是事后才想起的:这些库设计时压根没认真对待向前/向后兼容。
- 又慢又胖:Java 自带序列化的性能和体积是出了名的差。
一句话:方便是真方便,但它把「跨语言、安全、可演化、高效」这四样几乎全卖了。
3. JSON / XML / CSV:够用,但有几个坑
跨语言的标准格式里,JSON、XML、CSV 是最常见的。它们是文本格式,人能读,也确实「够用」——尤其是跨组织交换数据时,能让两个公司在格式上达成一致,本身就比格式漂不漂亮重要得多。
但「够用」不等于没坑,几个我真的踩过的:
① 数字精度——这是最隐蔽的杀手。 JSON 区分字符串和数字,但不区分整数和浮点,也不规定能精确表示到多少位。这里得补个背景:计算机存小数普遍用一种叫 IEEE 754 双精度浮点数(double) 的格式,它能精确表示的整数上限是 2⁵³(约 9×10¹⁵,9 千万亿)。超过这个数,double 就只能存一个「最接近的近似值」,末尾几位会被悄悄舍掉。偏偏 JavaScript 只有一种数字类型,而且就是这个 double——所以任何超过 2⁵³ 的整数进了 JS,都会被改值。
最经典的就是雪花 ID(Snowflake,一种 64 位的全局唯一 ID):它有 19 位十进制数字,远超 2⁵³。后端返回这么一个 ID,前端 JSON.parse 一解析,末几位就变成了 0——不报错,数据就是悄悄错了。X(Twitter)的 API 干脆把每个帖子 ID 返回两遍,一个是 JSON 数字、一个是字符串,就是为了让 JS 用字符串那份绕开这个坑。我自己后来的习惯是:只要一个数会进 JS、又必须精确(ID、金额、时间戳),就当字符串传。
② 二进制不支持。 JSON/XML 没有二进制类型,只能 Base64 编码塞进字符串,体积涨三分之一,还得靠 schema 约定「这个字段要按 Base64 解」。
③ CSV 没 schema、还很模糊。 CSV 自己不带任何「哪一列是什么含义、什么类型」的说明,全靠应用约定;加一列就得手动改解析逻辑。值里出现逗号或换行怎么办?转义规则虽然有正式规范(RFC 4180,就是定义 CSV 该怎么写的那份标准文档),但不是所有解析器都老实按它实现。
这里顺带说一下 JSON Schema——它是一份「用来描述并校验一段 JSON 应该长什么样」的规则文件(比如规定 port 字段必须是 1–65535 的整数)。它很强大,能写条件分支(满足 A 就要求 B)、能引用别处的 schema;但也正因为强大而笨重:解析远程引用、推理条件规则、保证 schema 自身改动的前后兼容,都很费劲。
还有一类「二进制版 JSON」(MessagePack、CBOR、BSON 等,思路都是把 JSON 直接编成更紧凑的二进制)。但因为它们仍然不带 schema,字段名还得原样塞进字节里,省不了多少。拿书里那个例子说:
{ "userName": "Martin", "favoriteNumber": 1337, "interests": ["daydreaming", "hacking"]}去掉空白的 JSON 是 81 字节,MessagePack 编出来 66 字节——省得有限,还把人能读这个优点丢了,不太划算。真正的提升要靠带 schema 的二进制格式。
4. Protocol Buffers:用字段号换紧凑
Protobuf(Google 出品,和 Facebook 的 Thrift 是近亲)要求任何数据都得先有 schema:
syntax = "proto3";message Person { string user_name = 1; int64 favorite_number = 2; repeated string interests = 3;}同样那条记录,protobuf 编出来只要 33 字节,不到 JSON 的一半。省在哪?关键是那几个数字 = 1 = 2 = 3——字段号(field tag)。编码后的字节里根本不存字段名,只存字段号 + 类型 + 值,字段号就像字段名的紧凑别名。再加上 varint(变长整数)——一种「数值越小、占的字节越少」的整数编码法:普通 int64 不管多小都固定占 8 字节,varint 则让 −64~63 只用 1 字节、1337 这种用 2 字节,越大才占越多——体积就这么压下来了。
字段号也正是 protobuf 处理 schema 演进(schema evolution)的核心。一条记录就是「各字段编码后首尾相接」,每段靠字段号标识、靠类型标注。由此推出几条规则:
| 操作 | 能不能做 | 为什么 |
|---|---|---|
| 改字段名 | ✅ 随便改 | 编码里根本没有字段名 |
| 改字段号 | ❌ 绝对不行 | 所有已存数据都会失效 |
| 加字段 | ✅ 用一个新字段号 | 老代码遇到不认识的号,靠类型标注算出该跳过几个字节,完整跳过——向前兼容成立 |
| 删字段 | ✅ 但字段号要永久保留(reserved) | 否则将来复用这个号,会和残留的老数据撞车 |
| 改类型 | ⚠️ 部分可以,有截断风险 | 32 位 int 改 64 位:新读旧没问题,旧读新可能把值截断 |
这里那条「加字段时老代码靠类型标注跳过未知字段」的设计,正是对第 1 节那个丢字段问题的正面回答:protobuf 的解析器知道一个不认识的字段有多长,于是能干净地跳过去而不破坏它。
我自己踩过的坑就是那条「字段号绝对不能复用」。有人删了个字段、过段时间又拿同一个号加了个语义完全不同的新字段,结果老数据里残留的值被新代码按新含义解读出来,排查时一脸问号。删字段一定要
reserved把号占住。
5. Avro:把 schema 拆成「写的」和「读的」
Avro(2009 年从 Hadoop 里长出来的)也用 schema,但思路和 protobuf 不太一样,差异挺有意思。它的 schema 长这样:
{ "type": "record", "name": "Person", "fields": [ {"name": "userName", "type": "string"}, {"name": "favoriteNumber", "type": ["null", "long"], "default": null}, {"name": "interests", "type": {"type": "array", "items": "string"}} ]}注意:没有字段号。同样那条记录,Avro 编出来 32 字节,是所有格式里最紧凑的。紧凑到什么程度?编码后的字节里既没有字段号,也没有字段名,甚至没有类型——就是一串值首尾相接。一个字符串只是「长度 + UTF-8 字节」,没有任何东西告诉你它是字符串。
那怎么解析?只能严格按 schema 里字段的顺序,逐个用 schema 说的类型去读。 这意味着:解码的人必须拿到和编码时一模一样的 schema,错一点全错。
读写 schema 分离
Avro 的精髓在这儿。它把 schema 分成两份:
- writer’s schema:写数据时用的版本,就是编码用的那份。
- reader’s schema:读数据的程序所期望的版本,可以和 writer 的不一样。
解码时 Avro 同时拿这两份 schema 做字段名匹配来对齐差异:
- writer 有、reader 没有的字段 → 忽略;
- reader 想要、writer 没写的字段 → 用 reader schema 里声明的默认值补上。
由此 Avro 的演化规则就和 protobuf 不同了,它围绕「默认值」:
- 加/删字段,只能动有默认值的字段。 加一个有默认值的字段:用新 schema 的 reader 读老数据,缺的字段自动补默认值。
- 想允许 null,必须用 union 类型(
["null", "long"]),而且 null 要放第一个分支才能当默认值。Avro 不像某些语言那样「啥都能是 null」,强迫你显式声明——这其实是在帮你防 Tony Hoare 口中那个「十亿美元的错误」。 - 改字段名靠 reader 里的 alias:向后兼容,但不向前兼容。
writer’s schema 从哪来?
既然解码必须有 writer 的那份 schema,可又不能把整个 schema 塞进每条记录(那 schema 比数据还大),怎么办?看场景:
| 场景 | 做法 |
|---|---|
| 一个大文件、几百万条同 schema 的记录 | schema 在文件开头只写一次(Avro 的 object container file) |
| 数据库里逐条写、各条 schema 可能不同 | 每条记录头上带个版本号,去 schema 注册表查对应 schema(Kafka 的 Confluent Schema Registry 就这么干) |
| 网络连接双向通信 | 建连时协商好 schema 版本,整条连接都用它(Avro RPC) |
而 Avro 没有字段号这件事,带来一个 protobuf 比不了的优势:对动态生成的 schema 友好。比如你想把一张关系表导出成二进制文件,可以直接从表结构自动生成 Avro schema,列名变字段名;哪天表加列删列了,重新生成一份新 schema 导出就行,读的人靠字段名照样能对上。换成 protobuf,字段号往往得人工分配,每次改表都得有人小心翼翼地维护「列名→字段号」的映射,还不能复用旧号——这事 Avro 设计之初就考虑了,protobuf 没有。
这一段是我做数据管道时最有共鸣的。Kafka + Avro + Schema Registry 几乎是流式数仓的标配:生产者注册 schema 拿到版本号,消息里只带号,消费者按号取 schema 解码;注册表还顺手帮你在上线前校验 schema 改动兼不兼容。开篇那个「上游悄悄改格式」的事故,如果走的是带注册表的 Avro 而不是裸 JSON,很可能在生产者注册新 schema 那一步就被拦下来了。
6. 体积对比 & schema 的附加价值
把同一条记录的几种编码放一起:
| 编码 | 体积 | 字节里存了什么 |
|---|---|---|
| JSON(去空白) | 81 B | 字段名 + 值(文本) |
| MessagePack | 66 B | 字段名 + 值(二进制) |
| Protocol Buffers | 33 B | 字段号 + 类型 + 值 |
| Avro | 32 B | 只有值(靠 schema 顺序解析) |
省字节当然好,但 DDIA 强调:带 schema 的二进制格式,真正的价值不止是紧凑:
- schema 本身就是文档,而且因为解码必须用它,它不可能过期——不像手写文档总会和现实脱节。
- 能在上线前做兼容性检查(配合 schema 注册表)。
- 静态类型语言能从 schema 生成代码,编译期就有类型检查。
代价是数据不再人类可读,得先解码。所以它和「无 schema 的 JSON」其实给了你同一种灵活度(新旧格式混存),但额外多了保证和工具。书里也提醒一句:别让同时存在的 schema 格式太多,否则运维会变复杂。
7. 数据怎么流动:四种模式
到这儿格式聊完了。但「兼容性」是编码方和解码方之间的关系,所以接下来的问题是:数据到底从谁流向谁?书里讲了四种典型模式,我按自己最熟的顺序过一遍。
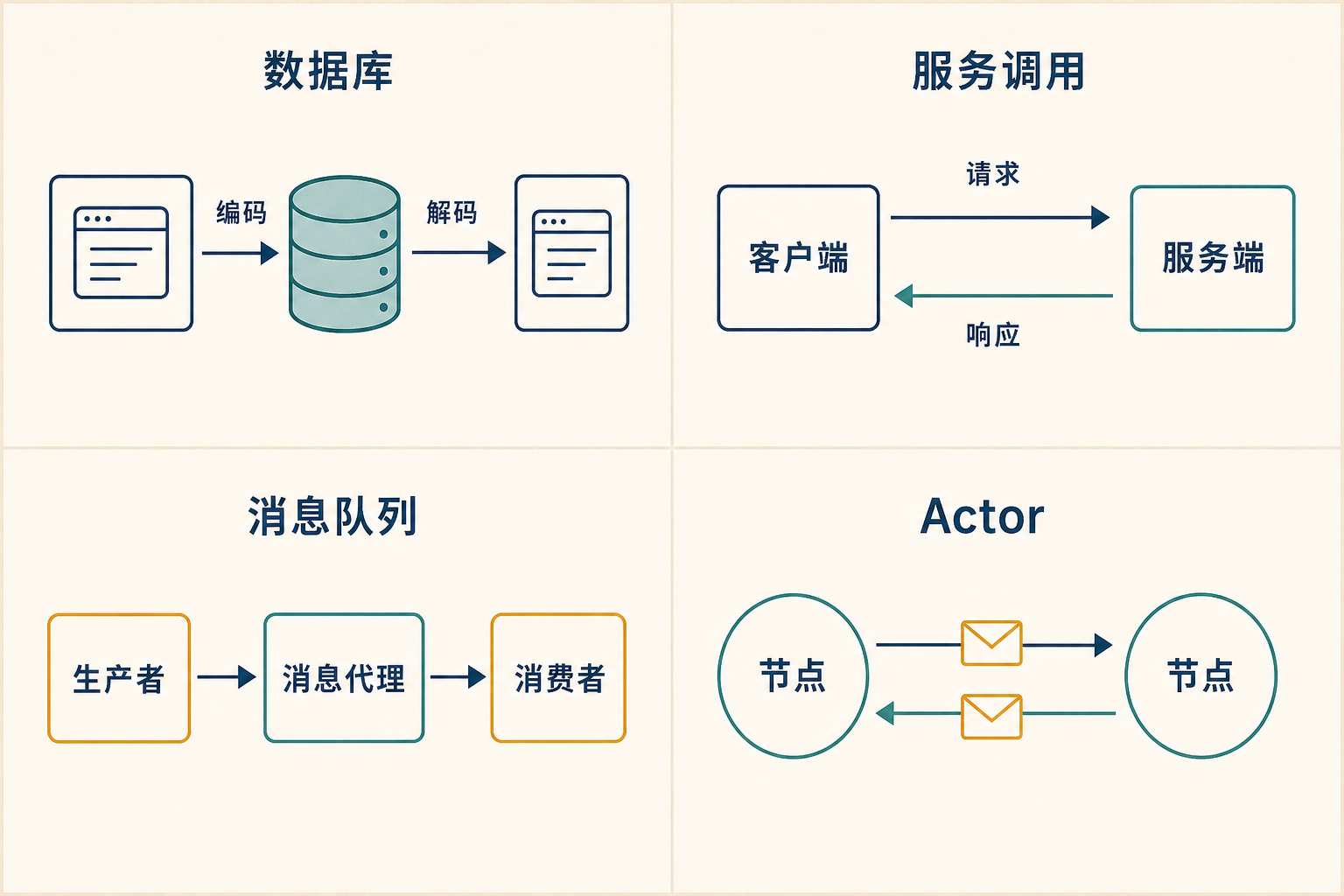
7.1 通过数据库:写给未来的自己
数据库里,写的进程编码、读的进程解码。哪怕只有一个进程在用,读的那个「未来的自己」也可能是升级后的新版本——所以向后兼容是底线,否则你以后读不出自己今天写的东西。
而多个进程同时访问、滚动升级期间新旧版本并存时,新版写、老版读也会发生,所以向前兼容同样需要。
这一节最让我有感触的就是那句 data outlives code:部署新代码,几分钟就把老版整个换掉了;但库里那条五年前的数据,还是五年前的编码。具体落地有几种处理:
- LSM-tree 在 compaction(后台把多个小文件合并、整理成大文件的过程,见上一篇)时,顺手就把老数据重写成了新格式。
- 关系库加一个带 null 默认值的列通常不重写存量数据,读到老行时现场补 null。
- 但复杂迁移(单值改多值、拆表)还是得真刀真枪重写,常常在应用层做,而且迁移期间维持前后兼容至今仍是个难题。
所以 schema 演进让整个库看起来像是用同一个 schema 编的,底下其实混着各个年代的版本。归档/快照则不同:导出时一般统一用最新 schema,写一次就不可变,特别适合 Avro object container file,或者干脆转成列存的 Parquet。
7.2 通过服务:REST 与 RPC
进程间走网络,最常见是客户端/服务端:服务端把 API(service)暴露在网上,客户端去调。微服务架构的一个核心目标就是让各服务能独立部署、独立演化——这又意味着新旧版本必然同时在线,编码必须跨版本兼容。
REST 是建立在 HTTP 之上的设计风格(用 URL 标识资源、用 HTTP 的缓存/认证/内容协商)。它对面站着的是 RPC(remote procedure call,远程过程调用):RPC 的核心想法是「让你调一个远程服务时,写起来跟调本地函数一模一样」。历史上一长串这类技术(EJB、RMI、DCOM、CORBA、SOAP)都基于这个想法,但 DDIA 的态度很明确:这个「假装成本地调用」的抽象(术语叫 location transparency,位置透明)根本是错的。远程调用和本地调用是两种东西:
- 本地调用结果可预测;网络请求会因为完全不受你控制的原因失败。
- 本地调用要么返回、要么抛异常、要么不返回;网络请求多一种结局——超时,你压根不知道对面到底执行了没有。
- 于是重试可能导致重复执行,除非你做幂等。
- 延迟天差地别,参数还得编码成字节(不能像本地那样传指针),跨语言还有类型对不齐的问题(又是 2⁵³)。
REST 的一部分吸引力,恰恰在于它不假装:它不把一次网络通信看成「调一个函数」,而看成「读写远端的一份资源」——GET 取回一份资源、PUT 写回它的新状态,来回传输的是数据状态本身,而不是一次函数调用。
兼容性上,服务比数据库简单一点:可以合理假设服务端先全部升级、客户端后升级,于是只需要请求向后兼容、响应向前兼容。难点在于 RPC 常跨组织边界——服务提供方管不了客户端,兼容性可能得维持到天荒地老,逼不得已就只能同时维护多个 API 版本(版本号放 URL 或 Accept 头里)。
这一节还顺带提了一串「客户端怎么找到服务」的话题,核心就一句:服务实例随时可能增减、迁移,客户端得有办法找到当前活着的那个。手段从简单到复杂:写死 IP(服务一搬家就失效)→ DNS(用域名解析出 IP,互联网就靠它)→ etcd / ZooKeeper 这类注册中心(服务启动时来登记、定时报活,客户端来查谁在线)→ service mesh(服务网格,如 Istio、Linkerd):给每个服务旁边塞一个叫 sidecar 的小代理进程,由它统一接管「找服务」、加密通信(TLS)、以及可观测性(谁在调谁、流量多大、哪里出错的监控与追踪)。
7.3 工作流与持久化执行
一笔支付要串起反欺诈、扣卡、入账好几个服务调用,这串步骤叫工作流(workflow),每步是一个任务(task)。问题是:服务架构里没法用一个数据库事务把这几步包起来,万一扣了卡没入账呢?
持久化执行(durable execution,如 Temporal、Restate) 的解法是给工作流提供恰好一次(exactly-once)语义:它把每个 RPC 调用和状态变更,都先记进一份持久日志(WAL,write-ahead log,预写日志——先把「我要做 / 我做完了这件事」写进日志再继续,崩溃后照着日志就能恢复到断点)。这样任务失败重跑时,之前已经成功做过的调用就不再真的执行,而是直接把上次记下的结果返回——相当于从断点接着往下走,而不是从头再来一遍。
代价也很实在,而且几乎都围绕同一个要求——代码必须能「原样重放」:
- 外部服务(比如第三方支付网关)自己仍得幂等,你得记得给它们传唯一 ID。
- 框架靠按相同顺序重放相同的 RPC 来工作,所以随便调换函数调用顺序就可能引入未定义行为;用了随机数、系统时钟这类非确定性代码也会出问题。
- 因此不要去改一个已有工作流的代码,而应该把新代码作为新版本单独部署——老的调用继续用老版本重放,只有新调用走新代码。
这条「别改已有 workflow,要发新版本」其实又是 data outlives code 的变体:那些正在重放的历史执行,就是活得比代码久的「数据」。
7.4 事件驱动:消息队列与 Actor
最后一种:发送方不直接连接收方,而是把事件 / 消息丢给一个中间人——消息代理(message broker),由它暂存、再投递。相比直接 RPC,好处是:能削峰缓冲、能在消费者崩溃后自动重投、不需要服务发现、能一对多广播、还能把收发双方解耦(发的人不关心谁来消费)。通信是异步的。
两种典型投递模式:队列(一条消息被其中一个消费者拿走)和发布/订阅 topic(所有订阅者都收到)。broker(RabbitMQ、Kafka、NATS、Redpanda,云上的 Kinesis / Pub/Sub)本身一般不管数据模型——消息就是一串带元数据的字节,用什么编码都行,所以常见做法又回到了 Avro/Protobuf/JSON + schema 注册表。
两个和兼容性直接相关的点:
- 有些 broker 消费完就删消息,有些可以永久保留——后者是事件溯源(event sourcing) 的前提。
- 消费者如果把消息转发到另一个 topic,要小心保留未知字段,否则就重演第 1 节数据库里那个丢字段的问题。
至于 actor 模型(Akka、Orleans、Erlang/OTP),它把并发逻辑封装成一个个 actor,每个 actor 有自己的私有状态,彼此只靠异步消息通信。有意思的是,前面被批评的「位置透明」放到 actor 模型里反而更合理了——因为 actor 模型本来就假设消息可能丢,所以「本地发消息」和「跨网络发消息」的语义差距没那么大,不像 RPC 那样硬要把不可靠的网络伪装成可靠的本地调用。但只要你想做滚动升级、新旧节点互发消息,前后兼容还是躲不掉。
8. 收尾:兼容性是一种纪律
DDIA 第 5 章看起来在讲编码格式,JSON、protobuf、Avro 挑来挑去;但它真正讲的是一件事:你永远没法一次性升级整个系统,所以新旧必须共存,而共存的代价就是两个方向的兼容性。
用我自己的话把这一章归纳成几条:
- data outlives code。 代码几分钟换完,数据能躺五年。任何「改格式」的动作,都要先问一句:那些用老格式写下的数据怎么办?
- 向前兼容是真正的考验。 让旧代码容忍它不认识的东西,并且别在读改写里把未知字段弄丢——这一条贯穿了数据库、消息转发、actor 所有场景。
- schema 不是负担,是保险。 带 schema 的二进制格式给了你紧凑、文档、上线前的兼容性校验和代码生成;配上 schema 注册表,很多事故能在「注册新版本」那一步就被拦住。
- 选格式,本质是在选你愿意承受的演化方式:protobuf 用字段号换灵活,Avro 用读写 schema 分离换动态生成的友好,JSON 用人类可读换掉了精度和体积。
这又回到了这个系列反复出现的那句话——没有最好的方案,只有你愿意为哪件事付代价。