
A distributed system is one in which the failure of a computer you didn’t even know existed can render your own computer unusable. 一台你压根不知道存在的机器出了故障,却能让你自己的机器也跟着没法用——这就是分布式系统。 ——Leslie Lamport
0. 一次「读副本读到旧值」的事故
有个后台系统做了读写分离来给主库减压:写走主库,读走只读副本(read replica)。上线没多久,用户开始反馈一个很反常的现象——刚提交完一条记录,页面一刷新,数据就不见了;再刷一下,又回来了。
排查了一圈,代码没问题,事务也确实提交成功了。最后定位到的原因是这样的:写成功落进了主库,但只读副本还没把这条写同步过来(复制是有延迟的);用户刷新时这次读请求恰好被负载均衡分到了那个还没追上的副本,于是读到了「写之前」的旧状态。等副本追上,再刷新就又正常了。
数据一点没丢,只是某个副本一时落后了。这正是 DDIA 第 6 章的主题。开篇 Kleppmann 指出了一句很关键的话:如果你要复制的数据永远不变,那复制是天底下最简单的事——把数据拷到每个节点一次即可。难点全都来自一件事:数据会变。
而处理这个「变」的方式,本质上都在回答同一个问题:当多个副本都要应用同一批写入时,谁说了算、按什么顺序应用?这条「给写入定序」的线,会贯穿单主、多主、无主三种复制方式;而你选择怎么定序,最终都落在一个更大的取舍上——一致性 vs 可用性/延迟。这是后面 CAP 的前奏,也是这一篇的主线。
1. 先分清:复制不是备份
动笔之前先把一个常被混淆的点理清:复制(replication)和备份(backup)不是一回事。
| 复制 | 备份 | |
|---|---|---|
| 目的 | 把一处的写快速同步到其他机器 | 留住过去某一刻的快照 |
| 对抗什么 | 机器/网络故障 | 人为误操作、软件 bug |
| 误删数据时 | 无能为力——删除也会被同步过去 | 能找回——快照里还留着 |
记一句话:复制对抗机器故障,备份对抗人和代码犯错。 两者其实互补——备份常常是搭建复制的第一步(先拿一份快照),而归档复制日志又可以是备份流程的一部分。
那为什么要复制?书里给了几条理由,也是这一章的目标:
- 高可用:一台机器(甚至一个机房、一个区域)发生故障,系统照常运行。
- 持久性:一台机器永久损坏,数据不丢。
- 低延迟:把副本放到离用户近的地方,访问更快。
- 扩展读吞吐:读请求分摊到多个副本上,单机承受不住的读量也能承受。
这一章先假设数据集小到一台机器装得下(装不下要分片,是下一章的事)。难点只剩一个:数据会变。书里讲了三种处理「变」的算法家族——单主、多主、无主。几乎所有分布式数据库都属于这三种之一。
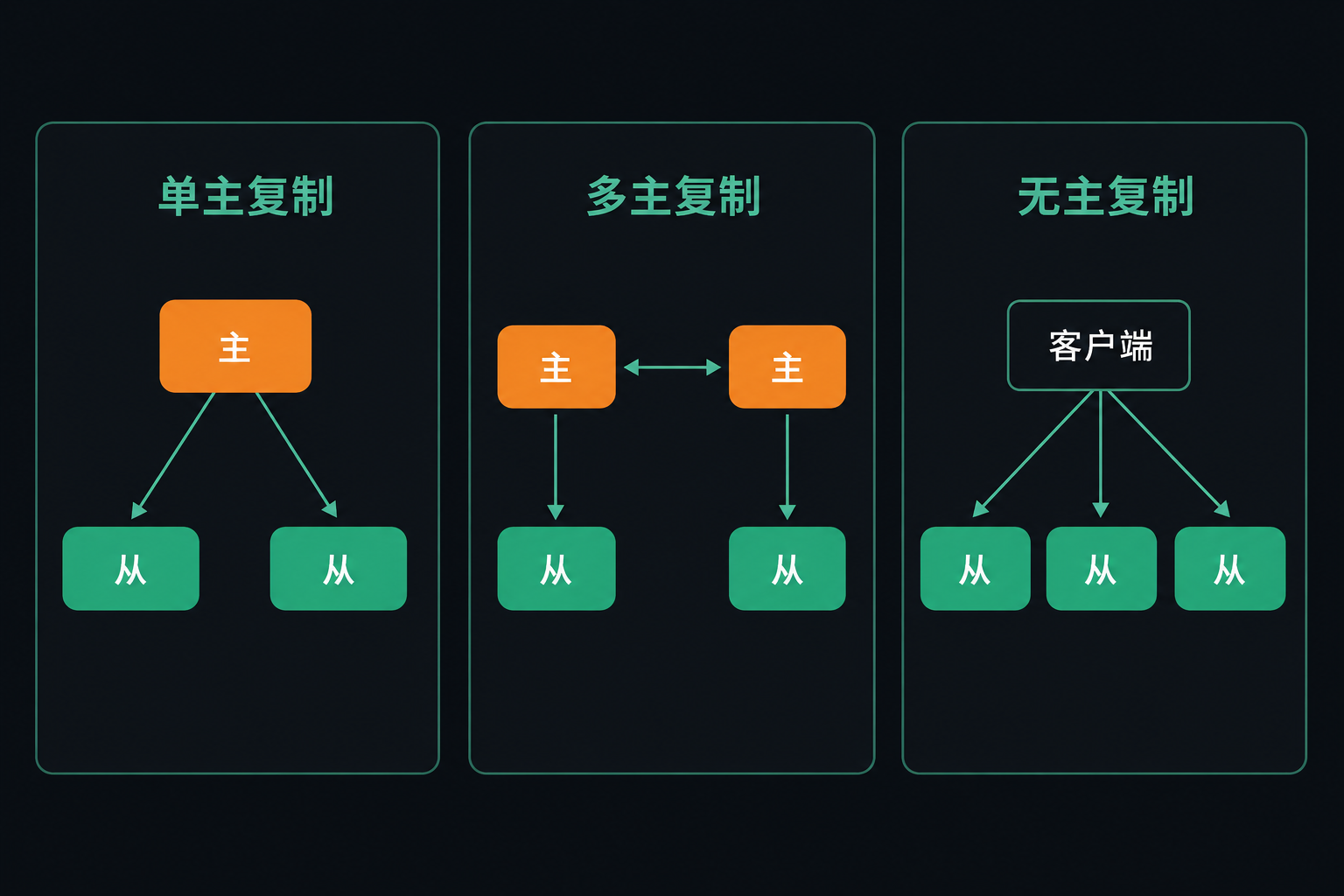
2. 单主复制:一个 leader 说了算
先定义两个词。每个存了一份数据的节点叫一个副本(replica)。单主复制(也叫主从、primary-backup、active/passive)是这么工作的:
- 选其中一个副本当 leader(主,也叫 primary)。客户端要写,只能发给 leader,它先把新数据写进自己的本地存储。
- 其他副本叫 follower(从,也叫只读副本、热备)。leader 每写一条,就把这次改动作为一条复制日志(replication log)发给所有 follower,follower 按和 leader 完全相同的顺序重放这些写。
- 客户端读,可以读 leader,也可以读任意 follower;但写只认 leader。
注意第 2 步那句「相同的顺序」——这就是单主模型定序的关键:由 leader 一个人决定全局写入顺序,所有 follower 照抄。这也是它能提供强一致的根本原因。
工程对应:单主是最常见的模型。PostgreSQL / MySQL 的主从、MongoDB、Kafka(每个 partition 一个 leader)、以及一批基于 Raft 共识算法自动选主的系统(etcd、CockroachDB、TiDB)都是单主。
同步还是异步:这一章的核心取舍
leader 把写转发给 follower 时,等不等 follower 的确认,是个关键的选择:
- 同步(synchronous):leader 要等 follower 确认收到了,才告诉客户端「写成功」。
- 异步(asynchronous):leader 发出去就不再等待,不等 follower 回应。
这两者的取舍,恰好是「一致性 vs 可用性/延迟」这条主线第一次正面登场:
| 同步复制 | 异步复制 | |
|---|---|---|
| 好处 | follower 一定有最新数据,leader 故障也不丢 | 快;follower 落后甚至宕机也不影响写入 |
| 坏处 | follower 一旦变慢,整个写就阻塞 | leader 故障,没同步出去的写就丢失 |
全部 follower 都同步是不现实的——任何一个节点出问题,整个系统就停止写入。所以实践中常见的是半同步(semi-synchronous):只让一个 follower 同步、其余异步,保证至少有两份最新数据(leader + 一个同步 follower);那个同步 follower 变慢了,就把另一个异步的临时提上来。再或者用多数同步(五个里三个同步),也就是后面要讲的 quorum。
工程对应——Kafka 的 acks:这套同步/异步取舍,做过 Kafka 的人其实天天在调,就藏在 producer 的 acks 参数里:
acks=0 发送后不等待确认 最快,最容易丢(纯异步)acks=1 leader 落盘即成功 leader 写完还没复制给 follower 就宕机 → 这条消息丢失acks=all 等 ISR 多数确认 等「与 leader 保持同步的副本集合」(ISR) 里足够多的副本确认acks=all 配上 min.insync.replicas,就是「多数同步」那一档。调这个参数,本质就是在「这条写能否容忍丢失」和「写要多快」之间做取舍。
顺带回答一个常被问到的问题:HDFS 的三副本,属于这三种里的哪一种? 答案是单主、同步复制那一档。客户端先从 NameNode(唯一的元数据中枢)拿到一条由 3 个 DataNode 组成的写入流水线,数据沿 DN1 → DN2 → DN3 链式传过去、逐个确认才算成功——有唯一的协调者、有确定的写入顺序,既不是多主也不是无主,只是它的「同步复制」采用了链式 pipeline 的形态(这种变体也叫链式复制)。
3. 节点故障了怎么办
复制的一大意义就是容错。但节点发生故障时,单主模型的处理对 leader 和 follower 完全不同。
Follower 故障:追赶恢复(catch-up)。 简单。每个 follower 本地都记着自己已经应用到哪一条了,重启后连上 leader,请求「我断线期间漏掉的那些写」,补完就追上了。
Leader 故障:故障切换(failover)。 这才是棘手的部分,要走三步:①判定 leader 真的失效了(通常靠超时——比如 30 秒没响应就判定它已下线);②选一个新 leader(要选数据最新的那个 follower,少丢数据;让所有节点对「谁是新 leader」达成一致,本身是个共识问题,第 10 章细讲);③把客户端的写流量切到新 leader。
failover 这一步处处是隐患,书里举的几个我印象很深:
- 丢写:异步复制下,新 leader 可能没收到旧 leader 最后那几条写。旧 leader 恢复后,这些写通常被直接丢弃——也就是说,你以为已经 commit、已经持久化的数据,其实已经丢失。
- 拖累外部系统:GitHub 出过一次真实事故——一个落后的 MySQL follower 被提成了 leader,它的自增主键计数器落后于旧 leader,于是重新分配了一批已经用过的主键。偏偏这些主键还被 Redis 当 key 用着,结果 MySQL 和 Redis 对不上,一些私密数据被发给了错误的用户。故障切换的破坏力,会通过主键这类东西扩散到数据库之外。
- 脑裂(split brain):某些故障下,两个节点都以为自己是 leader、都在接收写,又没有冲突解决机制,数据就会冲突、损坏。
- 超时设多长是个两难:太长,恢复慢;太短,一个负载尖峰或网络抖动就触发不必要的切换,而系统本来就在吃紧的时候误切,往往适得其反。
正因为这些问题没有简单解,不少运维团队宁可关掉自动切换、改成人工 failover——明明软件支持自动,他们还是选择慢一点、稳一点。
复制日志到底怎么传
leader 把改动发给 follower,「改动」有几种存法,差别对数据工程影响很大:
| 方式 | 怎么做 | 问题 / 代价 |
|---|---|---|
| 语句复制 | 把每条 SQL 原样转发给 follower 重放 | NOW()/RAND() 等非确定函数、自增列、触发器副作用会在各副本算出不同结果 |
| WAL 传输 | 直接把存储引擎的 WAL(预写日志,先写日志再落盘、崩溃可恢复,见第四篇)按字节发给 follower | 和存储格式紧耦合,leader/follower 版本必须一致 → 无法滚动升级 |
| 逻辑日志(行级) | 用一套独立于存储引擎的日志,描述行的增/删/改 | 解耦、能跨版本、易被外部程序解析 |
最后那个「逻辑日志」是重点。MySQL 的 binlog、PostgreSQL 的逻辑复制都属于这一类。它有个 WAL 传输给不了的好处:因为格式独立、容易解析,外部系统可以把它接出来用。
工程对应——CDC:这一节对数据工程几乎是核心知识。我们把业务库的 binlog 用 Debezium 这类工具捕获成一条变更流,灌进 Kafka,再分发给数仓、搜索索引、缓存——这套就叫 CDC(change data capture,变更数据捕获)。它本质上就是把数据库的复制日志接出来给别人复用:数据库原本用这条日志同步自己的 follower,CDC 不过是多接了一个「消费者」。上一篇讲编码时说「逻辑日志格式容易被外部解析」,落地就是这里。
4. 复制延迟的三个异常
回到开篇那个事故。异步副本会落后,于是出现了最终一致性(eventual consistency):只要你停止写入、等一会儿,所有 follower 最终都会追上、和 leader 一致。但「最终」这个词是故意含糊的——正常时延迟可能只有几毫秒,可一旦系统接近满载或网络出问题,延迟能上升到几秒甚至几分钟。延迟一大,就会出现三类很具体的异常:
下面三个名字,括号里是 DDIA 中文版的标准译名(方便你和别处对上号),但它们都挺抽象,所以我用一句人话当主标签:
| 异常(说人话) | 现象 | 标准译名 · 想要的保证 |
|---|---|---|
| 读不到自己刚写的 | 自己刚提交,刷新却读不到(读请求打到了没追上的副本) | 读己之写(read-your-writes):能看到自己提交的更新 |
| 读着读着倒退了 | 连刷两次,第二次比第一次还旧——像时间倒流 | 单调读(monotonic reads):不会读到比之前更旧的数据 |
| 因果被打乱 | 先看到回答、后看到问题 | 一致前缀读(consistent prefix):写有顺序,读到的顺序一致 |
逐个说:
- 读不到自己刚写的(读己之写):就是开篇那个事故。用户改了自己的资料,写进 leader,但回头一读打到了滞后的 follower,看着像没保存上。它只保证你看到自己的写,不保证看到别人的。
- 读着读着倒退了(单调读):用户连续读两次,第一次打到延迟小的副本、看到了新评论,第二次打到延迟大的副本、评论又不见了。数据没有丢失,但「先出现又消失」非常令人困惑。
- 因果被打乱(一致前缀读):先看到回答、才看到提问,仿佛对方未卜先知。有因果关系的两个写,被乱序看到了。这在分片数据库里尤其常见,因为不同分片各自独立、没有全局顺序。
这三个异常对应的解法,本质都是「想办法让读落到足够新的副本上」:
- 读不到自己刚写的:把「可能被自己改过」的数据读 leader(比如「自己的资料读主库、别人的资料读副本」);或写后一段时间内的读都打 leader;或客户端记住自己最后写入的位置,要求副本至少追到这个点才给读。
- 读着读着倒退了:让同一个用户始终读同一个副本(按用户 ID 哈希来选,而不是随机),自然就不会在新旧副本之间跳。
- 因果被打乱:把有因果关系的写放进同一个分片;或显式追踪因果依赖(version vector,第 6 节会讲)。
开篇那个事故,解决办法就是把「刚写完、用户读自己数据」的那种读强制打到主库——这正是 read-after-write 的第一种解法。
但要注意:这些保证都是应用层在给异步复制打补丁,复杂且容易写错。 最省心的做法,其实是直接选一个提供强一致(linearizability,第 10 章)加 ACID 事务的数据库,把整个集群当成单机来用。NoSQL 当年宣称强一致会限制扩展性,但这些年 NewSQL(CockroachDB、TiDB、Spanner 这类)已经能在强一致和可扩展之间兼顾了。当然,弱一致仍有它的位置——网络中断时更顽强、开销更低——所以这章后半段还要继续看那些更弱的模型。
5. 多主复制:多个 leader,代价是冲突
单主有个明显短板:写全得过那一个 leader,连不上它就无法写入。
多主复制(multi-leader,又叫 active/active、双向复制)放宽了这点:允许多个节点都接受写,每个 leader 同时又是其他 leader 的 follower。同步多主等价于单主,所以真正值得关注的是异步多主——任何一个 leader 都能独立处理写,哪怕它和其他 leader 断了联系。
它主要用在两种场景:
- 跨地域部署:每个区域放一个 leader,写在本地区域处理、再异步同步到其他区域。这样跨区延迟对用户是隐藏的,某个区域整个发生故障或区域间网络抖动,各区域还能各自独立运转。
- 离线 / 协作应用:日历 App、Google Docs、Figma 这类。每个设备、甚至每个打开了同一文档的浏览器 tab,都是一个本地副本(leader),本地先写、联网了再异步同步。这套思路有个新名字叫同步引擎(sync engine),能离线编辑的叫 offline-first,连服务商关停了都还能用的叫 local-first。
典型架构长什么样:跨地域那种,是每个区域内部各跑一整套「单主 + 若干 follower」的集群,区域之间再让各自的 leader 互相异步复制——本地用户就近写本区域的 leader,跨区同步在后台异步完成。协作那种,则是每台设备/每个浏览器 tab 各存一份本地副本,通过一个中继服务器(或设备间 P2P)把各自的改动同步给其他人。值得说清的是:数据库层面的「真正的多主」其实很少见、也常不被推荐(后面会讲它有多容易出问题),所以 2026 你最常遇到的多主,反而是协作类应用——每个客户端就是一个 leader。
多主的好处都来自「放弃了单主那个全局定序者」,而代价也正来自这里——冲突:两个 leader 同时改了同一条记录,改成了不同的值。这是单主天然没有的问题(只有一个地方定序,不可能产生冲突)。如何解决冲突,是多主的核心难题:
- 避免冲突:让同一条记录的写总是路由到同一个 leader(比如按用户归属固定到某个区域)。从单个用户视角看,这其实又退化成单主了。但一旦 leader 需要切换(区域故障、用户迁移),避免就失效了。
- LWW(last write wins,最后写入者赢):给每个写标上时间戳,留时间戳最大的。简单,但「并发写谁更新」本身是未定义的——所以 LWW 的真实含义是:并发写时随机选一个保留、丢弃其余的,代价是丢数据。而且严重依赖时钟同步(一台机器时钟快了,它的写就总是胜出)。
- 手动解决:把所有并发值(叫 siblings)都存下来,下次读时全返回,让应用或用户去合并。经典反例是 Amazon 购物车——用集合并集来合并,结果被删掉的商品会「复活」。
- 自动合并:CRDT 与 OT。这是为协作场景设计的两类算法,能把并发修改自动合并、保证所有副本收敛到同一状态(strong eventual consistency)。CRDT(无冲突复制数据类型)给每个字符/元素一个不可变的唯一 ID 来定位,OT(操作转换)则记录操作的位置索引、再根据并发操作做变换。OT 多用于 Google Docs 这类实时文本协作,CRDT 则是 Automerge、Yjs 这些 local-first 库的底层基础。
多主之间还有个「拓扑」问题(写沿哪些路径传播):环形、星形、全连接。环形和星形只要一个节点发生故障就可能中断传播链;全连接容错好,但写可能因为各链路快慢不同而乱序到达——又是因果问题,得靠 version vector 来定序。多主在很多数据库里是后加的功能,和自增主键、触发器这些容易冲突,所以常被认为是「能不用就不用」的高风险功能。
6. 无主复制:没有 leader,靠投票
第三种走得更远:干脆不要 leader,任何副本都能直接接收客户端的写。这一思路由 Amazon 2007 年的 Dynamo 系统推广开来,所以这类库(典型如 Cassandra)也叫 Dynamo 风格。
没有了 leader,做法就不同了:客户端把写并行发给多个副本,读也从多个副本并行读。因为没有 leader 定序,也就没有故障切换这回事——所有副本平等,一个发生故障,客户端用其他副本的响应即可。每个值都带版本号,客户端读到多个值时取最新的那个。
典型架构(以 Cassandra 为例):一圈对等节点,没有主从——注意这里的「副本」是分布在不同机器、甚至不同机架/不同区域上、靠网络连起来的,跟「一台机器里插几块硬盘做冗余」的磁盘阵列(RAID)完全是两回事:RAID 是单机硬件冗余,机器一旦损坏就全部丢失;无主复制能承受整台机器、整个机架、乃至整个区域发生故障。每个 key 用哈希算出该落到其中哪 RF(replication factor,副本数,通常是 3)个节点上。客户端任意连接一个节点,这个节点就充当本次请求的协调者(coordinator),把读/写转发给那几个副本,按你设的一致性级别(比如 QUORUM,即下面要讲的 w=r=2)等够回应就返回。
这对数据开发有什么用:你最可能遇到无主复制的地方,是把 Cassandra 这类宽表存储当「服务层」——埋点行为流、时序指标、用户画像/特征这种「写入量大、还要能横向扩」的场景。当你用 Spark 读写它时,那个一致性级别就是你手里的旋钮:读用 ONE 最快,但很可能漏掉刚写进去、还没扩散开的最新值(就是 w + r 不够大);读用 QUORUM 才稳;跨地域还有 LOCAL_QUORUM,只等本区域、快但可能偏旧。懂了 w + r > n,你才说得清这几个挡位各自在拿一致性换什么、什么时候该用哪个。
那个一时没收到写的副本,靠三种机制追上来:
- 读修复(read repair):客户端读的时候发现某副本返回了旧值,顺手把新值写回去。
- 提示移交(hinted handoff):某副本发生故障时,别的副本临时替它存下这些写(叫 hint),等它恢复再转交。
- 反熵(anti-entropy):后台进程不断比对副本间的差异、把缺的数据补齐。
Quorum:w + r > n 的简单算术
核心问题来了:写发给多少个算成功、读到多少个算可信?设总共 n 个副本,每次写要 w 个确认、每次读要查 r 个。只要满足:
w + r > n读和写的副本集合就必然有交集,于是你读的 r 个里至少有一个拿着最新值。常见配置是 n=3、w=r=2,能容忍一个节点发生故障。
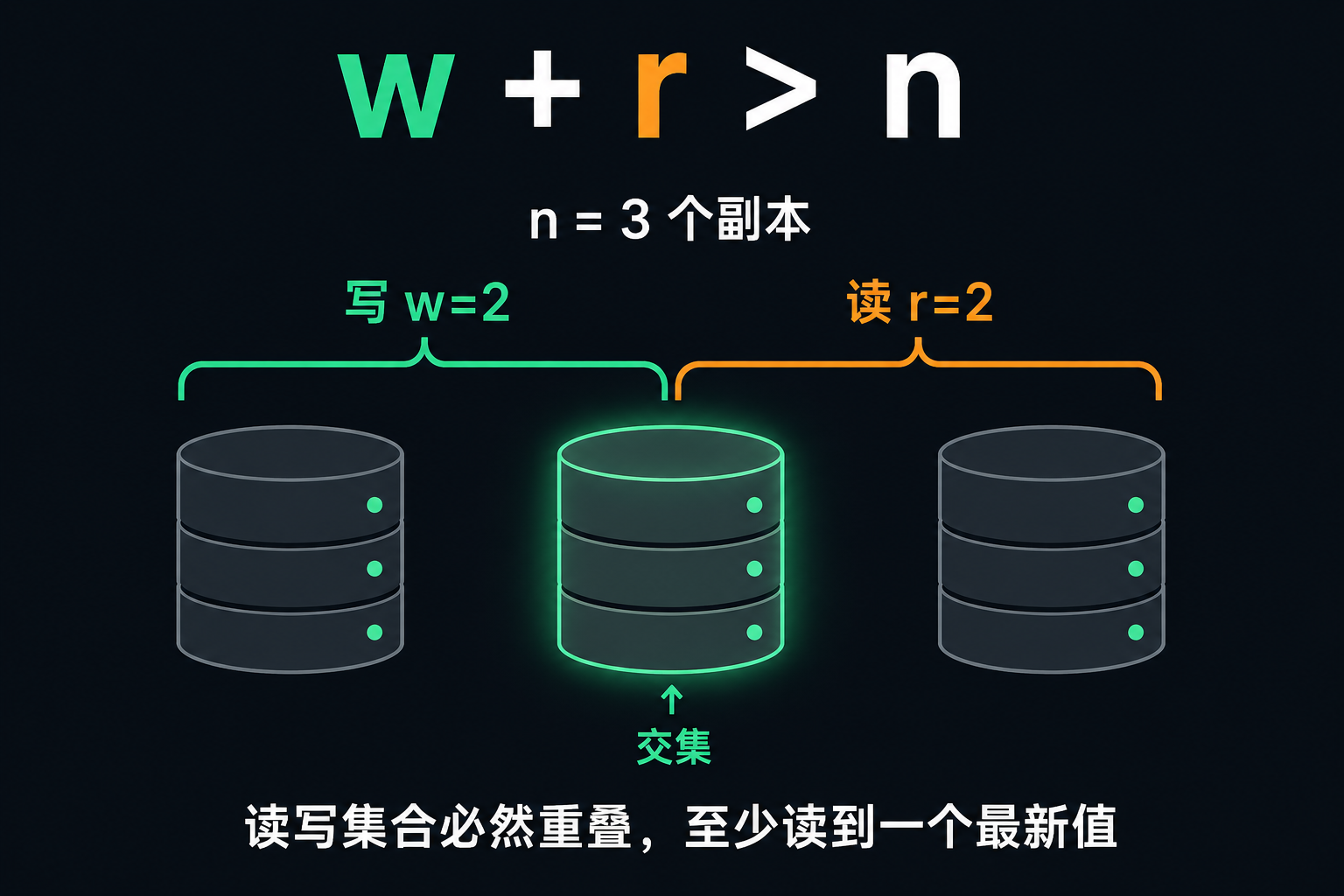
但别把 quorum 当成绝对保证。书里列了许多边界情况会让它失效:rebalance(数据在节点间搬迁)期间读写集合可能不再重叠、读写并发时读可能看到也可能看不到新值、写只成功了一部分(不到 w 个)却不回滚、用物理时钟判新旧会无声地丢失写入……所以 Dynamo 风格的库本质是为「能容忍最终一致」的场景优化的,w 和 r 调的是「读到旧值的概率」,而不是绝对的「一定读到最新」。
怎么判断两个写是不是「并发」
先说为什么要费这个劲,不然这一节会显得很突兀。无主(和多主)下,同一个 key 可能在不同节点上被并发写,而且各节点收到这些写的顺序还不一样:节点 1 可能先收到 A 再收到 B,节点 3 反过来。如果每个节点见到一个写就不加判断地覆盖本地值,副本之间就会永久分叉、各执一词,再也收敛不到一起。
要收敛,系统必须先分清一件事:眼前这个新写,到底是「基于旧值改出来的」(那它就该覆盖旧值),还是「和旧值同时发生、写的时候根本不知道有对方」(那是真冲突,不能覆盖,得保留两份让上层去合并)?这正是前面 LWW、siblings、CRDT 那些冲突处理手段的前提——你得先认出冲突,才谈得上解决它。而光看时间戳分不清这两种情况,于是引出了那个贯穿全书的关键概念:happens-before(发生在先)。
操作 A happens before 操作 B,意思是 B 知道 A、依赖 A、或建立在 A 之上。如果两个操作谁都不 happens-before 谁,它们就是并发的。
注意:并发和物理时间无关。两个操作哪怕隔了很久,只要当时双方互不知情(比如网络断了),它们就是并发的。判断靠的是给每个 key 维护版本号;多副本时则用版本向量(version vector)——每个副本各持一个版本号的集合——而不是物理时钟(时钟在分布式里并不可信,第 9 章专门讲)。版本向量让数据库能区分「这是一次覆盖」还是「这是一对需要保留的并发冲突」。书里那个购物车例子(两个客户端并发往同一个购物车加东西,最后保留几个 siblings)把这套算法演示得很清楚。
7. 收尾:多副本,从你提交第一个写就开始付费
DDIA 第 6 章看起来在讲三种复制方式怎么选,但绕回到开篇那句话,它真正讲的是一件事:「同一份数据放多台机器」一旦遇上「数据会变」,难点全在于给写入定序,而定序方式的不同,就是你愿意在哪里付费的不同。
把三种模型放到「定序」这条线上看,就清楚了:
| 模型 | 谁来定序 | 换来什么 | 代价 |
|---|---|---|---|
| 单主 | 一个 leader 全局定序 | 简单、强一致 | leader 是瓶颈和单点,故障切换有损 |
| 多主 | 每个 leader 各自定序 | 跨地域低延迟、能离线 | 冲突,要靠 LWW/CRDT 解决 |
| 无主 | 没人定序,靠读写 quorum 投票 | 高可用、无故障切换 | 读到旧值/冲突,靠版本向量兜底 |
而横在所有选择之上的,是同步 vs 异步这杆秤:同步把成本付在写入延迟和可用性上(一个慢副本拖累整体),异步把成本付在一致性上(有人会读到旧值、有人会读到冲突的值)。最终一致性那句「最终」没有时间上限,所以工程上还得监控复制延迟,把这个「最终」量化出来、落后太多就告警。
这一章我最大的收获,是别再把「多副本」想成「多存几份更安全」那么简单。一旦数据会变、一旦不止一处能写,你从提交第一个写的那一刻起就已经在为一致性付费了——区别只在于,你是把成本付在写入延迟上,还是付在「总有人会读到旧值」上。选哪种复制,就是选你愿意在哪一端付费。还是这个系列那句老话——没有最好的方案,只有你愿意为哪件事付代价。