
Clearly, we must break away from the sequential and not limit the computers. 我们必须摆脱「一切都排成一条线、塞进一台机器」的做法,别再束缚住计算机的能力。 ——Grace Hopper,《Management and the Computer of the Future》(1962)
0. 一个停在 99% 的 Spark 作业
做数据这些年,最让我有感触、也反复让我吃过亏的一件事,叫数据倾斜(data skew)。
场景几乎每次都一样:一个跑批作业,按用户聚合行为日志,GROUP BY user_id,或者拿一张事实表去 JOIN 维表。任务提交下去,999 个 task 两分钟就跑完了,偏偏剩一个 task 停在 99%,一停两小时,最后还因为内存耗尽(OOM)失败。整个集群几百个核,全程陪着这一个 task 空等。
排查下来,根因每次都一样:Spark 在 shuffle 阶段,会按 key 的哈希把数据行分配到若干个分区(partition)里分别计算。而恰好有一个 key 的值占了全表九成的行——可能是未登录用户被填了默认值 -1,可能是一个跑量的系统账号,也可能是一批 null。这些行的哈希值相同,于是全部落入同一个分区,由同一个 task 处理。其他 task 早已空闲,这一个还在独自承担几乎全部的数据。
应对办法也很常规:给这个热 key 加一个随机后缀,把它拆成上百份分别计算,最后再去掉后缀合并一次。后面会看到,这个做法在书里有个正式的名字,思路完全一致。
先把这个故事放在这里,因为它正是 DDIA 第 7 章的主题在批处理里的缩影。一次 shuffle 把数据按哈希分配到各分区,本质上就是一次「按哈希分片」;某个 key 的数据量过大,它落在哪个分区,哪个分区就成了热点。而这一章要讲的,正是当一份数据大到一台机器装不下、需要拆开分布到多台机器(这就是分片,sharding)时:按什么拆、拆完怎么定位、热点怎么处理。
开篇 Kleppmann 把分片的动机讲得很直接:分片追求的是线性扩展——10 台机器,承载 10 倍的数据、10 倍的吞吐。但这个「10 倍」只在一个前提下成立:负载分布得足够均匀。
1. 先分清:分片不是复制,也不是网络分区
动笔前先把三个长得相似的词区分清楚,免得后面相互混淆。
一个分布式数据库通常用两种方式分布数据:一种是把同一份数据在多台机器上各存一份,这是上一篇讲的复制(replication);另一种是数据量太大、或写入太频繁,单机已经承受不住,于是把数据拆成小块、不同的块放在不同机器上,这就是分片。一句话区分:
| 复制 | 分片 | |
|---|---|---|
| 作用 | 同一份数据,多机各存一份 | 一份数据拆成块,不同机器各存一块 |
| 解决什么 | 容错、低延迟、扩展读 | 扩展存储和写入——单机存不下、也写不过来 |
| 一条记录在几台机器上 | 在每个副本上都有 | 只属于某一个分片 |
实践中两者几乎总是配合使用:先分片,再让每个分片各自做复制。所以一条记录虽然只属于一个分片,却仍然存在于好几台机器上(也就是它所在分片的多个副本)。复制的那一整套(单主/多主/无主、同步/异步)和如何分片是两件独立的事,因此本章不再涉及复制,只讨论数据划分本身。
顺带一提,「shard」这个词的来历有点意思:一种说法是它来自网游《网络创世纪》——一颗魔法水晶被打碎成许多碎片(shard),每块碎片折射出一个平行的游戏世界,后来「一个 shard」就成了「一台平行服务器」的意思,再后来被借用到数据库领域。
为什么说分片是个「重量级」的方案。复制在大小规模下都有用(小集群同样需要容错),但分片基本只在大规模时才划算。原因是它会带来不少复杂度:你得为每条记录选一个分区键(partition key)——也就是决定它落到哪个分片的那个字段,分区键相同的记录都放进同一个分片。这个选择很关键:知道分区键,定位一条记录非常快;不知道,就只能逐个分片搜索一遍。而且分片方案一旦确定,再修改极其麻烦。所以书里的建议很务实——单机能承受就不要分片(如今一台机器能承受的量,大得超乎想象)。
2. 两种基本分法:按范围,还是按哈希
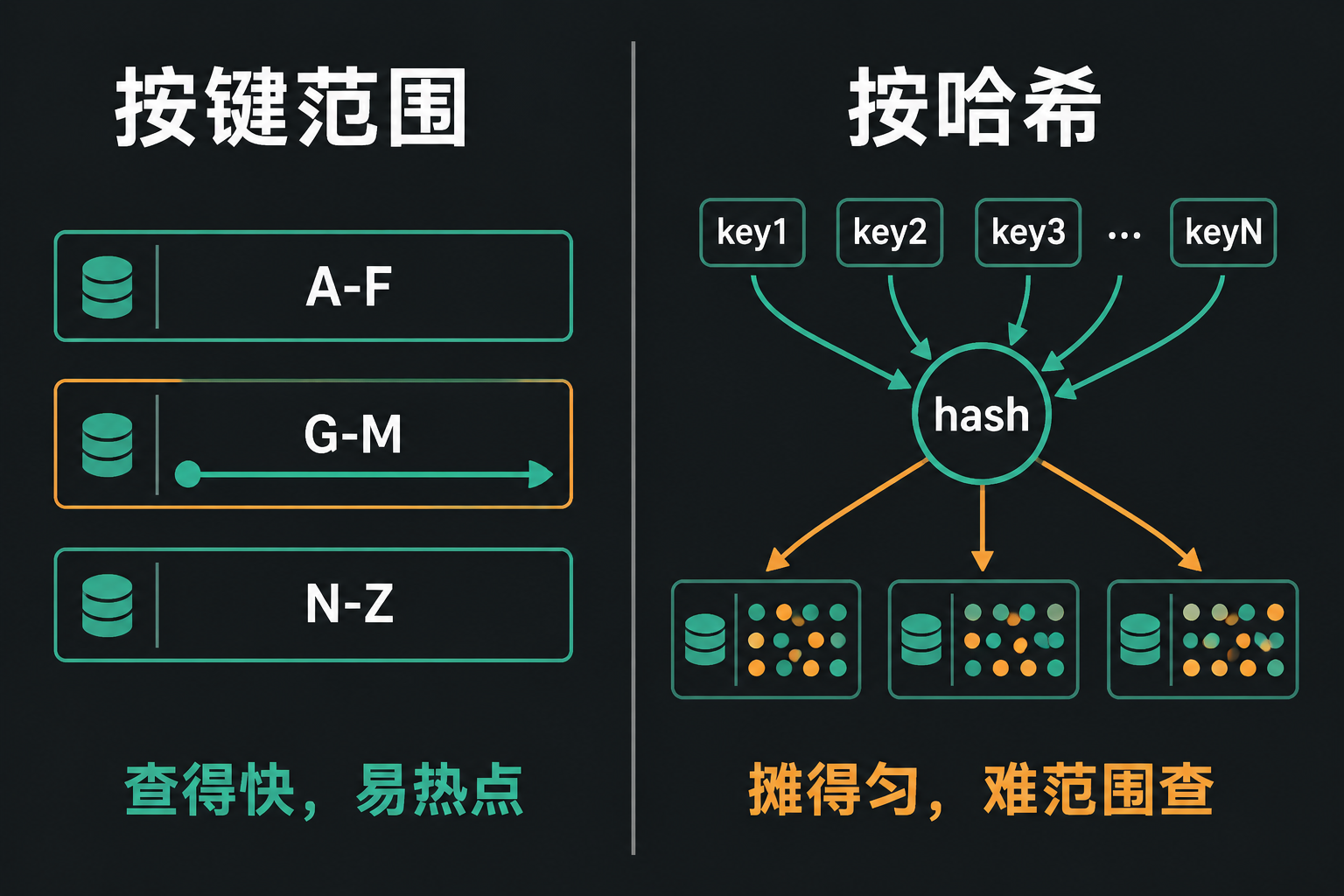
划分键值数据,主流就两种思路。它们的区别,正是这一章会反复出现的那道两难第一次登场:是让相关的数据挨在一起(这样查得快),还是让数据均匀分散(这样负载平衡、不堆热点)。
按键范围分片(key-range),像一套纸质百科全书:A、B 开头的词条放第 1 卷,T 到 Z 放第 12 卷。每个分片负责一段连续的键区间。要找某个键,先看它落在哪个区间,直接取对应那一卷即可。区间不必等宽——数据分布不均,边界就得跟着数据走(A、B 开头的词条多就单独成卷,T–Z 少就合在一卷)。分片内部的键是按顺序存放的(B-树或 SSTable,见第四篇),所以范围扫描非常快:想取某个传感器某个月的全部读数,一次连续扫描就能完成。
它的短板也恰恰来自「有序」:顺序写入容易产生热点。假设键是时间戳,分片就按时间分段,比如一个分片对应一个月。数据边采集边写入,所有写入就全部涌向「当月」那个分片,使它过载,而其他分片闲置。这正是开篇那种倾斜的另一种形态。规避的办法是不要把时间戳放在键的开头,而是用 传感器ID + 时间戳 作为键,写入就分散到各个传感器上了——代价是按时间范围跨多个传感器查询时,得对每个传感器分别扫描一次。
按哈希分片(hash)换一种思路:先把分区键送进一个哈希函数——给它任意输入,它会返回一个看起来随机、但同一输入永远得到同一结果的数字。好的哈希函数能把再倾斜的输入也转换成均匀分布。然后按哈希值来分片。这样相邻的键(比如连续的时间戳)会被分散到各处,写入自然就均匀了,也就没有了顺序写热点。代价正好相反:键的顺序被打乱,范围查询就失效了——相邻的键散落在所有分片上,你只能逐个分片去查询。
(这里的哈希不需要密码学级别,足够分散即可。但有一点要注意:不要用编程语言内置的那类哈希——比如 Java 的 Object.hashCode(),同一个 key 在不同进程里算出来可能不同,用来分片会直接出错。)
把两种放在一起对比,主线就很清楚了:
| 按键范围(key-range) | 按哈希(hash) | |
|---|---|---|
| 怎么划分 | 键排序,一段连续区间归一个分片 | 对键算哈希,按哈希值分片,打乱顺序 |
| 范围查询 | 快——相邻键在同一分片,一次扫完 | 低效——相邻键散落各分片,得查询所有分片 |
| 顺序写 | 危险——单调递增的键全部涌向最新分片,形成热点 | 安全——哈希打乱顺序,写入均匀分散 |
| 偏向 | 让相关数据挨在一起 | 让负载均匀分散 |
| 典型系统 | HBase、Bigtable、CockroachDB、MongoDB(范围模式) | Cassandra、DynamoDB、Kafka(按 key 分区) |
有一种折中值得一提:使用复合键,把第一段用来算哈希、决定分片,其余部分在分片内保持有序。这样跨分区键的范围查询依然低效,但在同一个分区键下、按后面的字段做范围查询仍然高效(因为它们都在同一个分片里)。Cassandra 的 (partition key, clustering key) 就是这个设计;数据仓库里 BigQuery 的「分区键 + 聚簇列」、Snowflake 的「微分区 + 聚簇键」也是同一个思路——先按一个键分布,再在块内按另一个键排序,扫描和压缩都更高效。
换个角度看:开篇那个 Spark shuffle,就是「按哈希分片」的临时版本——它的目的就是把数据均匀分布、便于并行计算,代价就是顺序丢失了。Kafka 给消息选 partition,默认也是按消息 key 算哈希,所以同一个 key 的消息一定进同一个 partition、保证有序,不同 key 则分散到各 partition 并行消费——你用到的正是「哈希分片」这一套取舍。
3. 倾斜与热点:均匀分布 ≠ 均匀负载
哈希能把键分布得很均匀,但这里有一个特别容易让人放松警惕的陷阱:键均匀,不等于负载均匀。
哈希保证的是「每个分片分到的 key 数量大致相同」。但如果某一个 key 本身被访问得格外频繁,它再怎么均匀地待在某个分片里,那个分片照样会被压垮。典型例子是社交媒体上的大 V:一个千万粉丝的账号发一条动态,瞬间引来海量读写,全部集中在同一个 key(这位大 V 的用户 ID,或那条动态的 ID)上。这种访问格外集中的 key 叫热 key(hot key),被它拖累的分片叫热点分片(hot shard)。哈希对这种「单点过热」无能为力——它能避免键分得不均,却避免不了某个键本身过于热门。
应对热点,书里给的办法分两层:
- 数据库层面:采用基于范围(键范围或哈希范围)的分片方案,把这个热 key 单独划入一个分片,甚至为它配一台专属机器。云数据库(如 DynamoDB)会自动完成这件事,称为自适应容量(adaptive capacity)。
- 应用层面:就是开篇那个办法——加盐(salting)。给热 key 加一个随机数,把对它的写入均匀拆成 N 份,分散到不同分片上。
加盐写成 SQL 就是常见的「两阶段聚合」,和书里「给热 key 加两位随机数字、拆成 100 份」是同一个做法:
-- 原始:user_id = -1 的行全部落入同一个 task,导致卡住SELECT user_id, count(*) FROM events GROUP BY user_id;
-- 加盐第一阶段:给 key 加一个 0~99 的随机后缀,热 key 被拆成 100 份,分到不同 taskSELECT user_id, salt, count(*) AS cFROM (SELECT *, floor(rand() * 100) AS salt FROM events) tGROUP BY user_id, salt;
-- 第二阶段:去掉盐,把 100 份合并起来SELECT user_id, sum(c) AS cnt FROM <上一步结果> GROUP BY user_id;但加盐不是没有代价的,它的代价正是主线的另一面:写入分散开了,读取就得重新汇总。本来一次就能读完的 key,现在分成 100 份,每次读取都得把 100 份全部读出来再合并。而且只有那几个真正的热 key 值得加盐——给海量的冷 key 都加,纯属增加开销——所以你还得额外维护一份记录:哪些 key 被加盐了。更麻烦的是热度会变化:一条爆款动态热上两三天就回落了;有的 key 在读取上热、有的在写入上热,还得分别处理。
这一节其实是开篇那个 99% 故事的推广:热点不是哈希没做好,而是真实世界的负载本就不均匀。分片能把数据分布均匀,却无法抹平人们对某些数据的偏好。
4. 重平衡:加减机器时,数据怎么搬
集群不是一成不变的:数据增长了要加机器,机器坏了要替换。把负载重新分摊到新的机器数量上,叫重平衡(rebalancing)。目标很明确:迁移得越少越好——重平衡要在网络上传输大量数据,传输期间系统还得照常读写,迁移过猛会把网络和节点一起拖累。
先看一个直觉上很顺、实际却很糟的做法:对节点数取模(mod N)。10 台机器,就把 哈希(key) % 10 当作机器编号,余数是几就放第几台。计算很简单,可一旦机器数 N 变了,问题就来了——从 3 台加到 4 台,% 3 全变成 % 4,几乎每个 key 的归属都变了,绝大多数数据都得迁移。这正是要极力避免的「无谓的大规模迁移」。
实践中有两类办法规避它,但本质是同一个思路:不要让「数据放在哪」直接等于「哈希 % 机器数」。
- 预先划分较多的固定分片:10 台机器,一开始就划分出 1000 个分片、每台先放 100 个。加机器时整块整块地把分片迁移过去,key 落在哪个分片不变,只调整「分片在哪台机器」这份映射。Citus、Elasticsearch 走的是这条路。
- 一致性哈希:把机器和 key 都映射到一个环上,加一台机器只接管它在环上紧邻的那一小段 key,其余部分原地不动。Cassandra 走的是这条路。
机制不必记住,记住这条直觉就够用:两者都做到「增减机器时只迁移一小部分数据」,而不像 mod N 那样几乎全部重排。 它正好解释了一个你会遇到的运维现象——为什么 Cassandra 扩容很顺畅,而像 MinIO 这种按哈希定位的存储,却不能随手加一块盘、必须整组整组地扩。
自动还是手动:一个可能引发雪崩的选择
分片的拆分和迁移,是让系统全自动决定,还是需要人工确认?
全自动很省心,云数据库(如 DynamoDB)号称能在几分钟内自动增减分片来应对流量起落。但全自动重平衡 + 全自动故障检测,凑在一起可能酿成大问题。书里这个连锁反应让我印象很深:某个节点只是临时过载、响应慢了一点,其他节点却判定它「已下线」,自动把它的负载迁走;迁移本身又要占用网络和节点,于是更多节点被拖慢、被误判为「已下线」,负载继续迁移……最终演变成级联故障(cascading failure)——明明没有机器真正损坏,整个集群却因为这套自动处置而瘫痪(这类分布式系统的连锁故障,第 9 章会专门讲)。
正因如此,很多团队宁可在系统里保留一道人工确认环节(human in the loop):自动算出一个建议的迁移方案,但需要管理员确认后才执行。慢一点,换来不出意外。在已知的流量高峰(双十一、热门赛事抢票)到来之前,手动提前重平衡,也比临场自动调度更稳妥。这和上一篇「不少团队宁可关掉自动故障切换」是同一个道理——自动化在出问题的当口往往适得其反,于是人们主动选择慢而稳。
5. 请求路由:我到底该连哪台机器
数据划分好、也能重平衡了,下一个问题很现实:客户端想读写某个 key,怎么知道该连哪台机器(哪个 IP 和端口)?这叫请求路由(request routing)。
它和普通的服务发现有一个关键区别:无状态服务的负载均衡可以把请求发给任意一个实例,但在分片数据库里,一个 key 只能由持有对应分片的那个节点来处理,发错了节点没有用。书里给了三种方式:
- 客户端连接任意节点(比如轮询)。如果正好命中,就直接处理;如果没命中,这个节点会替你转发给正确的节点,拿到结果再返回给你。
- 加一个路由层(routing tier):所有请求先到它这里,由它算出该由谁处理、再转发过去。它自己不处理请求,只充当一个「懂分片的负载均衡器」。
- 让客户端自己懂分片:客户端直接掌握分片→节点的映射,算好后直接连接正确的节点,不经过中间环节。
无论哪一种,都绕不开一个核心难题:「分片在哪台机器」这份映射,本身存放在哪里、由谁维护、如何保证它不出问题?让单个协调者说了算最简单,可它一旦宕机就全部失效;让协调者支持故障切换,又得防止脑裂(两个协调者各行其是,给出互相矛盾的分片分配)。
于是答案常常是:额外引入一个专门的协调服务,比如 ZooKeeper 或 etcd。这两者可以理解成一个小型的、专门存放「关键元数据」的高可用数据库——它只存放很少的数据(谁是 leader、哪个分片在哪台机器),但用共识算法(第 10 章的主题)保证这份元数据强一致、不会脑裂。每个节点上线时就到 ZooKeeper 登记,分片一旦变更归属,ZooKeeper 就通知路由层更新。
举几个例子:HBase 用 ZooKeeper 管理分片分配;Kubernetes 用 etcd 记录「哪个服务实例运行在哪里」;MongoDB 用自家的 config server 加 mongos 路由进程(就是上面第 2 种「路由层」);Kafka 现在则用内置的 Raft 共识(KRaft)自己实现了这套协调能力。做数据的人对这些组件多半不陌生——只是过去未必意识到,它们做的都是同一件事:用共识守住那份「分片在哪」的权威映射。
6. 收尾:查得快还是负载匀,分片只能给你一个
DDIA 第 7 章看起来在讲「一份大数据怎么拆、拆完怎么定位」,但绕回开篇那条线,它真正讲的是一个反复出现的两难:你既想让相关的数据挨在一起(这样查得快),又想让数据均匀分散(这样负载平衡、不堆热点)——可这两件事天生互斥,成全一个就得牺牲另一个。
整章的每个决策,其实都是这同一道选择题:
| 在哪里取舍 | 让相关数据放一起 | 让数据均匀分散 | 各自的代价 |
|---|---|---|---|
| 主键怎么分 | 按键范围:范围扫描快 | 按哈希:负载分布均匀 | 放一起则顺序写产生热点;分散开则范围查询失效 |
| 热 key 怎么办 | 单独成片,集中读取 | 加盐分散到多片 | 分散写入后,读取要重新汇总 |
这一章我最大的收获,是不要再把分片想得那么轻巧、以为「数据太多,拆开分散出去就行」。一旦拆开,你就再也回不到「相关数据天然在一起、负载天然均匀」的状态了——这两件好事不可兼得,你只能选择其一,并为另一件的缺失付出代价。